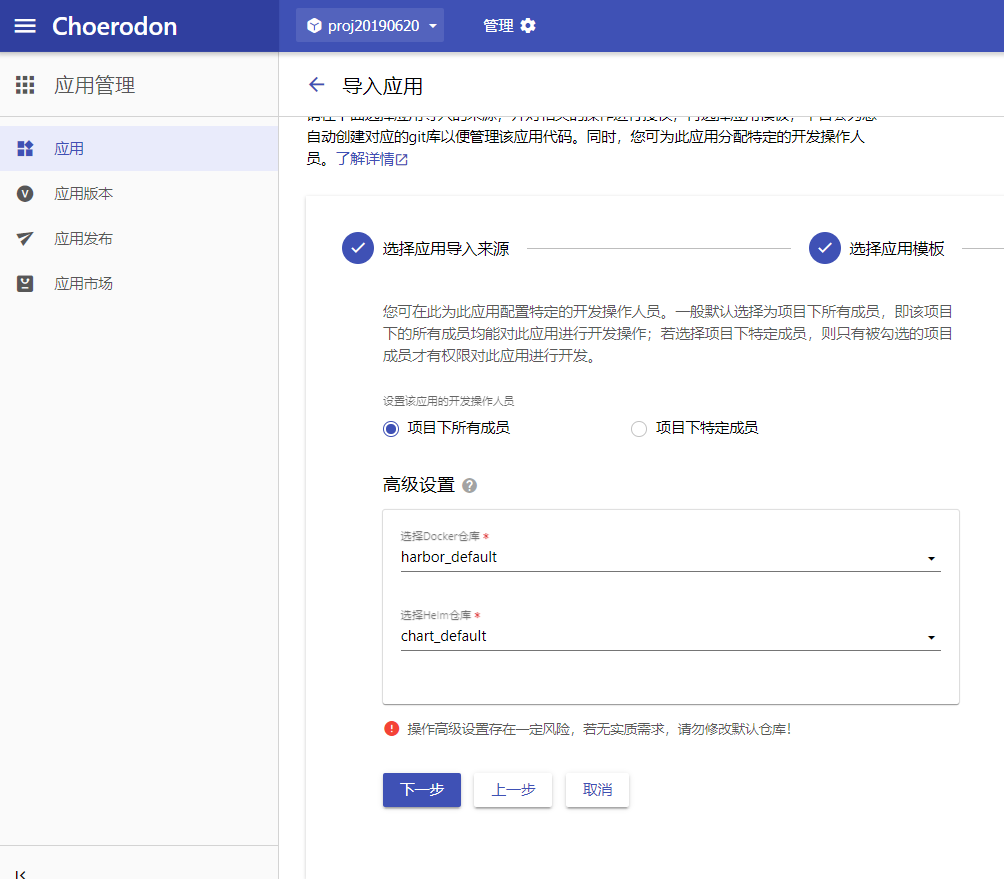
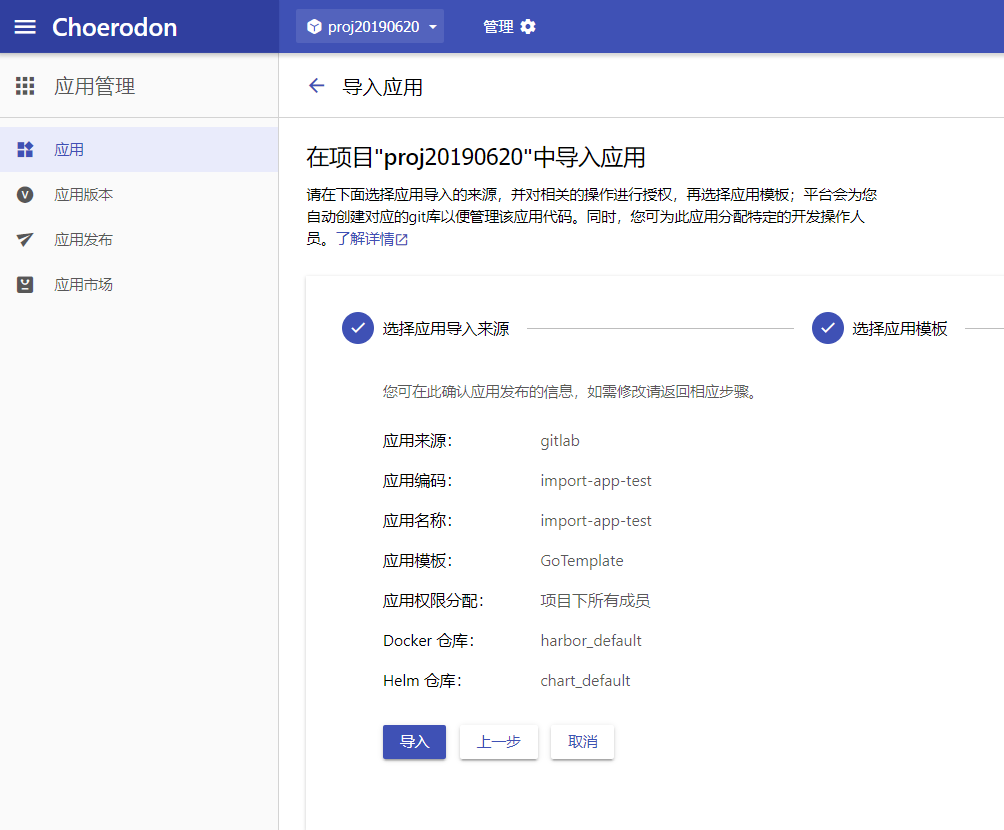
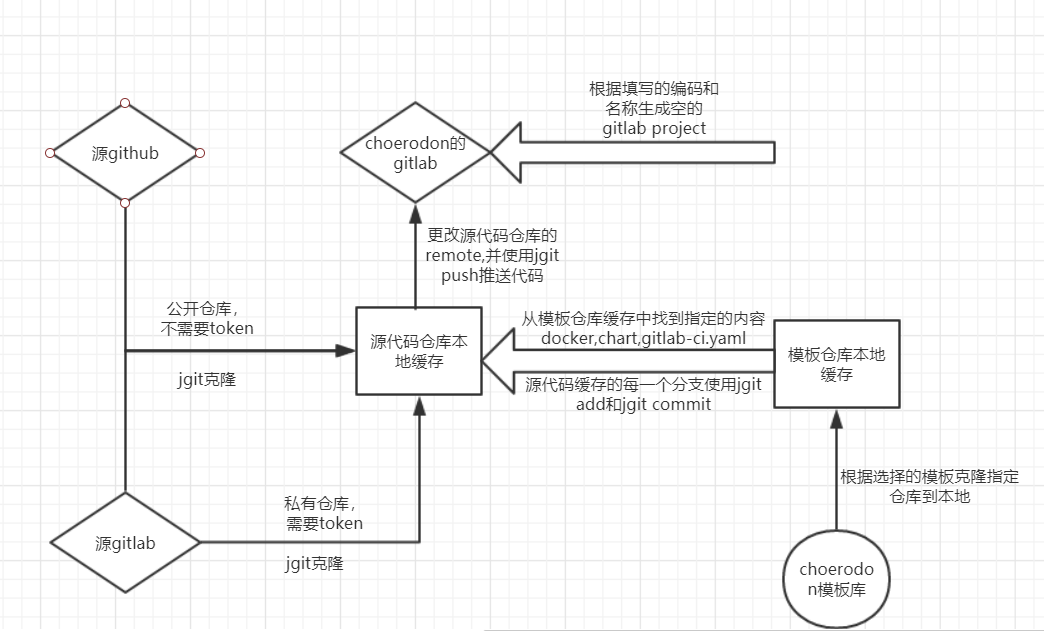
Choerodon猪齿鱼V0.23版本中的部署 > 应用部署 > 流水线功能在猪齿鱼中停用,需要切换为开发 > 应用流水线功能,相比于老版的流水线,新版本的应用流水线增强了猪齿鱼的管理功能,提供了更多的扩展。通过 Gitlab 和 猪齿鱼的 DevOps 实现提交代码后自动更新服务的流程。
前置条件
开发规范
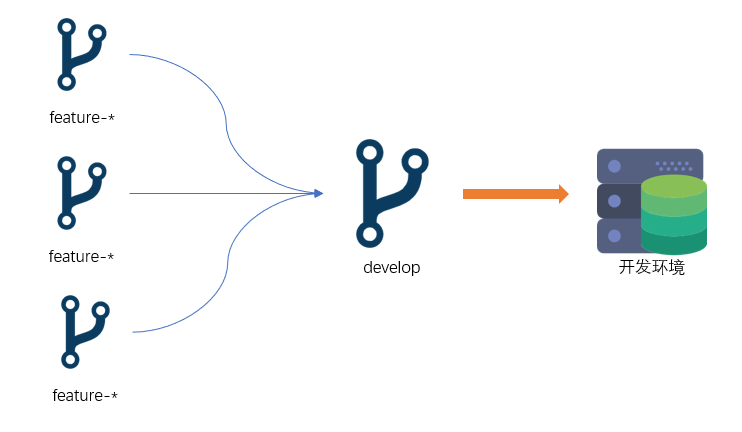
开发人员在特性分支(feature-*)进行功能开发,完成功能开发之后将特性分支合并到环境分支develop进行部署。
自动化部署配置
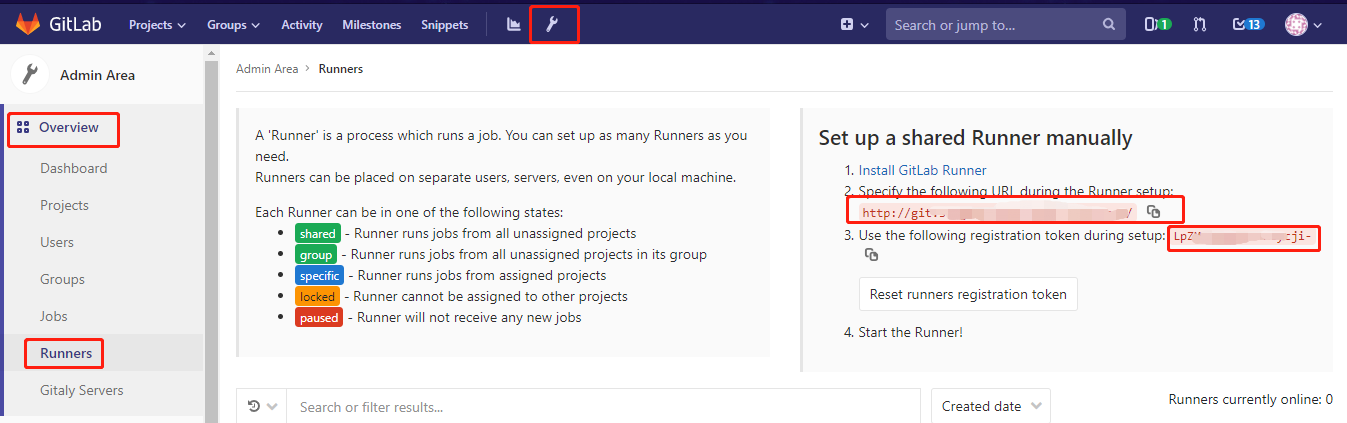
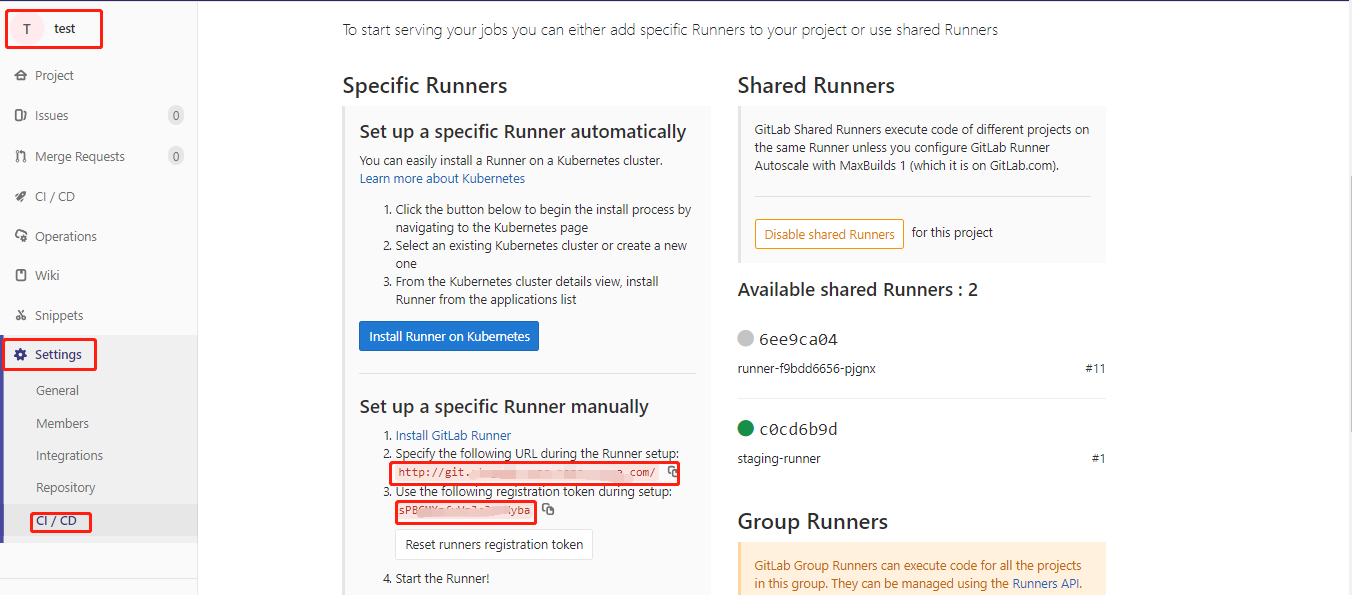
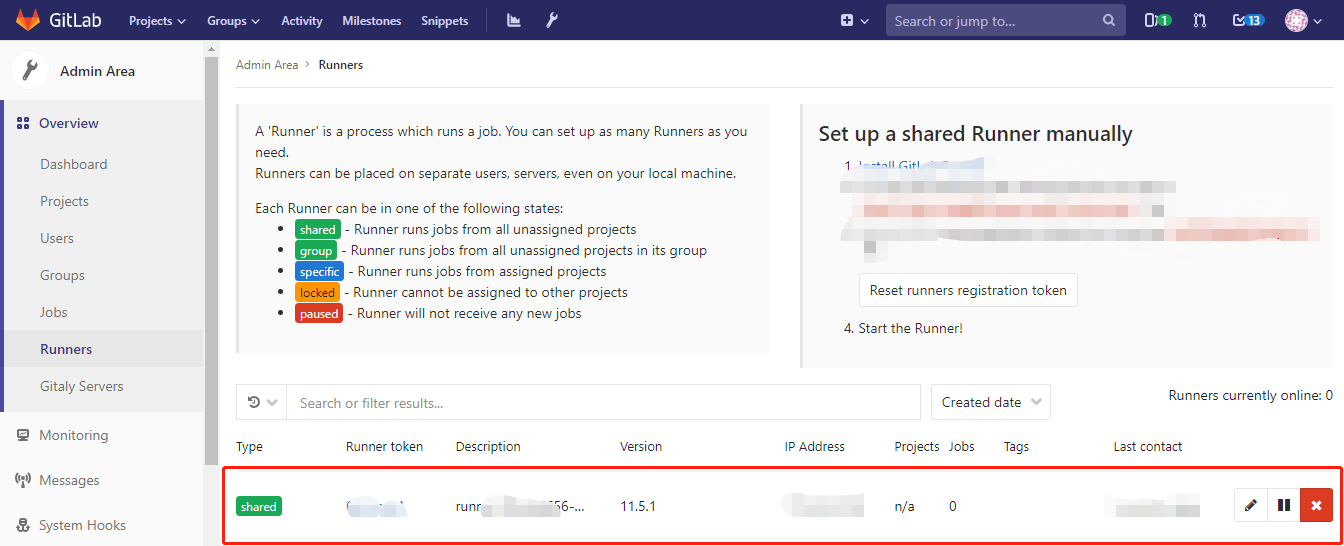
在猪齿鱼中配置 K8s Config Map
功能路径:应用部署 > 资源 > 资源视图 > 选择环境 > 配置映射
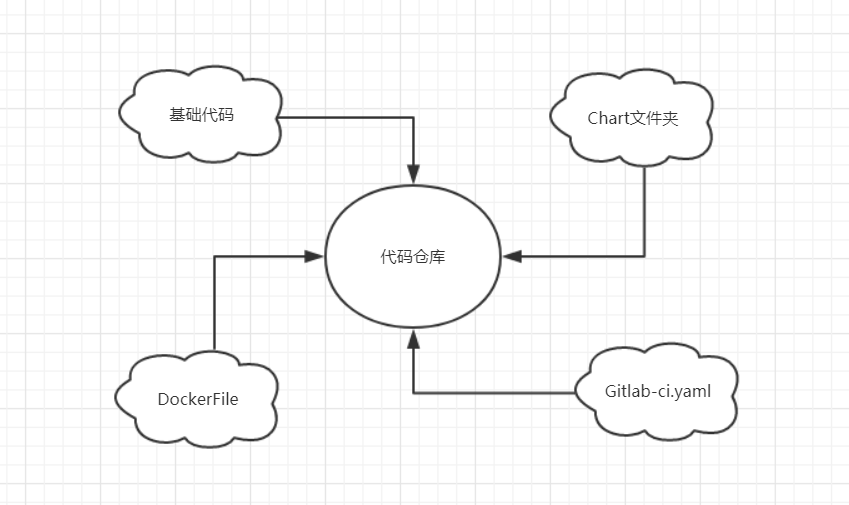
在配置映射中需要定义CM的名称,这里以hzero-dev为例,在配置映射中维护公共的环境变量,例如注册中心地址等.

调整 Chart 中的配置文件
创建完成配置映射之后,需要在k8s部署时读取cm配置,这一步需要调整项目下的helm配置。
注意配置的缩进,直接拷贝(Ctrl + V)IDEA会自动调整缩进,请使用Paste as Plain Text保证缩进不会被自动调整。

- charts/hzero-platform/templates/_helpers.tpl
{{/* vim: set filetype=mustache: */}}
{{- /*
service.labels.standard prints the standard service Helm labels.
The standard labels are frequently used in metadata.
*/ -}}
{{- define "service.image" -}}
{{- printf "%s:%s" .Values.image.repository (default (.Chart.Version) .Values.image.tag) -}}
{{- end -}}
{{- define "service.microservice.labels" -}}
choerodon.io/version: {{ default (.Chart.Version) .Values.image.tag }}
choerodon.io/service: {{ .Chart.Name | quote }}
choerodon.io/metrics-port: {{ .Values.deployment.managementPort | quote }}
{{- end -}}
{{- define "service.labels.standard" -}}
choerodon.io/release: {{ .Release.Name | quote }}
{{- end -}}
{{- define "service.match.labels" -}}
choerodon.io/release: {{ .Release.Name | quote }}
{{- end -}}
{{- define "service.logging.deployment.label" -}}
choerodon.io/logs-parser: {{ .Values.logs.parser | quote }}
{{- end -}}
{{- define "service.monitoring.pod.annotations" -}}
choerodon.io/metrics-group: {{ .Values.metrics.group | quote }}
choerodon.io/metrics-path: {{ .Values.metrics.path | quote }}
{{- end -}}
{{/*
Return the appropriate apiVersion for deployment.
*/}}
{{- define "app.deployment.apiVersion" -}}
{{- if semverCompare "<1.9-0" .Capabilities.KubeVersion.GitVersion -}}
{{- print "apps/v1beta2" -}}
{{- else -}}
{{- print "apps/v1" -}}
{{- end -}}
{{- end -}}
{{/*
Return the appropriate apiVersion for statefulset.
*/}}
{{- define "app.statefulset.apiVersion" -}}
{{- if semverCompare "<1.9-0" .Capabilities.KubeVersion.GitVersion -}}
{{- print "apps/v1beta2" -}}
{{- else -}}
{{- print "apps/v1" -}}
{{- end -}}
{{- end -}}
{{/*
Return the appropriate apiVersion for ingress.
*/}}
{{- define "app.ingress.apiVersion" -}}
{{- if semverCompare "<1.14-0" .Capabilities.KubeVersion.GitVersion -}}
{{- print "extensions/v1beta1" -}}
{{- else -}}
{{- print "networking.k8s.io/v1beta1" -}}
{{- end -}}
{{- end -}}
- charts/hzero-platform/templates/deployment.yaml
26~28行定义读取CM,CM的名称来自于values.yaml。
apiVersion: {{ include "app.deployment.apiVersion" . }}
kind: Deployment
metadata:
name: {{ .Release.Name }}
labels:
{{ include "service.labels.standard" . | indent 4 }}
{{ include "service.logging.deployment.label" . | indent 4 }}
spec:
replicas: {{ .Values.replicaCount }}
selector:
matchLabels:
{{ include "service.labels.standard" . | indent 6 }}
template:
metadata:
labels:
{{ include "service.labels.standard" . | indent 8 }}
{{ include "service.microservice.labels" . | indent 8 }}
SERVICE_CODE: {{ .Chart.Name | quote }}
annotations:
{{ include "service.monitoring.pod.annotations" . | indent 8 }}
spec:
containers:
- name: {{ .Release.Name }}
image: "{{ .Values.image.repository }}:{{ .Chart.Version }}"
imagePullPolicy: {{ .Values.image.pullPolicy }}
envFrom:
- configMapRef:
name: {{ .Values.configMap.name }}
env:
{{- range $name, $value := .Values.env.open }}
{{- if not (empty $value) }}
- name: {{ $name | quote }}
value: {{ $value | quote }}
{{- end }}
{{- end }}
ports:
- name: http
containerPort: {{ .Values.service.port }}
protocol: TCP
# readinessProbe:
# httpGet:
# path: /health
# port: {{ .Values.deployment.managementPort }}
# scheme: HTTP
readinessProbe:
exec:
command:
- curl
- localhost:{{ .Values.deployment.managementPort }}/actuator/health
failureThreshold: 3
initialDelaySeconds: 60
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 10
resources:
{{ toYaml .Values.resources | indent 12 }}
volumeMounts:
- mountPath: /Charts
name: data
{{- if not (empty .Values.persistence.subPath) }}
subPath: {{ .Values.persistence.subPath }}
{{- end }}
volumes:
- name: data
{{- if .Values.persistence.enabled }}
persistentVolumeClaim:
claimName: {{ .Values.persistence.existingClaim | default ( .Release.Name ) }}
{{- else }}
emptyDir: {}
{{- end }}
- charts/hzero-platform/values.yaml
6~7行定义了CM的名称,这里需要和猪齿鱼配置映射的名称匹配。
# Default values for hzero-platform.
# This is a YAML-formatted file.
# Declare variables to be passed into your templates.
replicaCount: 1
configMap:
name: hzero-dev
image:
repository: registry.choerodon.com.cn/hzero-hzero/hzero-platform
pullPolicy: Always
env:
open:
# 数据库地址
SPRING_DATASOURCE_URL: jdbc:mysql://db.hzero.org:3306/hzero_platform?useUnicode=true&characterEncoding=utf-8&useSSL=false
# Redis DB
SPRING_REDIS_DATABASE: 1
metrics:
path: /actuator/prometheus
group: spring-boot
logs:
parser: spring-boot
persistence:
enabled: false
service:
enabled: false
type: ClusterIP
port: 8100
name: hzero-platform
deployment:
managementPort: 8101
resources:
# We usually recommend not to specify default resources and to leave this as a conscious
# choice for the user. This also increases chances charts run on environments with little
# resources,such as Minikube. If you do want to specify resources,uncomment the following
# lines,adjust them as necessary,and remove the curly braces after 'resources:'.
limits:
# cpu: 100m
memory: 1.7Gi
requests:
# cpu: 100m
memory: 1.2Gi
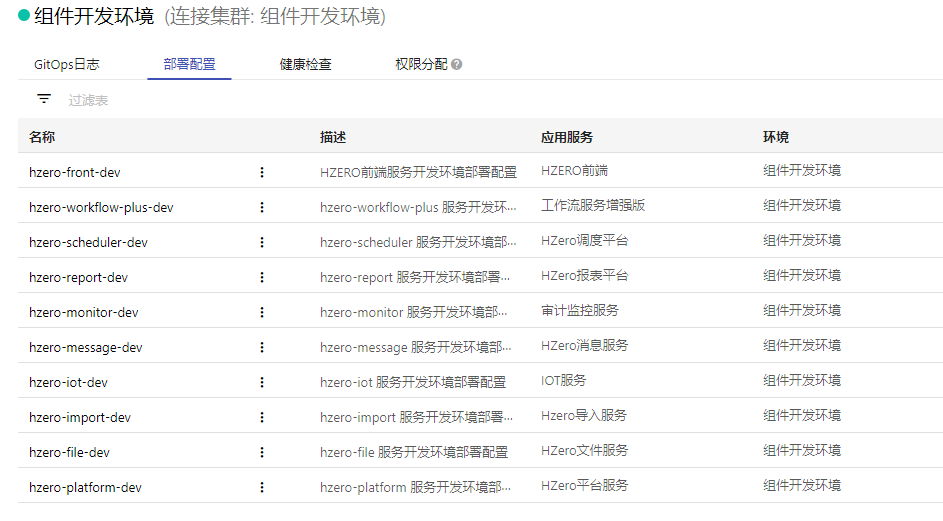
创建部署配置
功能路径:部署 > 应用部署 > 资源 > 创建部署配置
在部署配置选择对应服务,如果项目中有values.yaml文件,这里会自动带出。将环境相关的信息替换完成后保存。
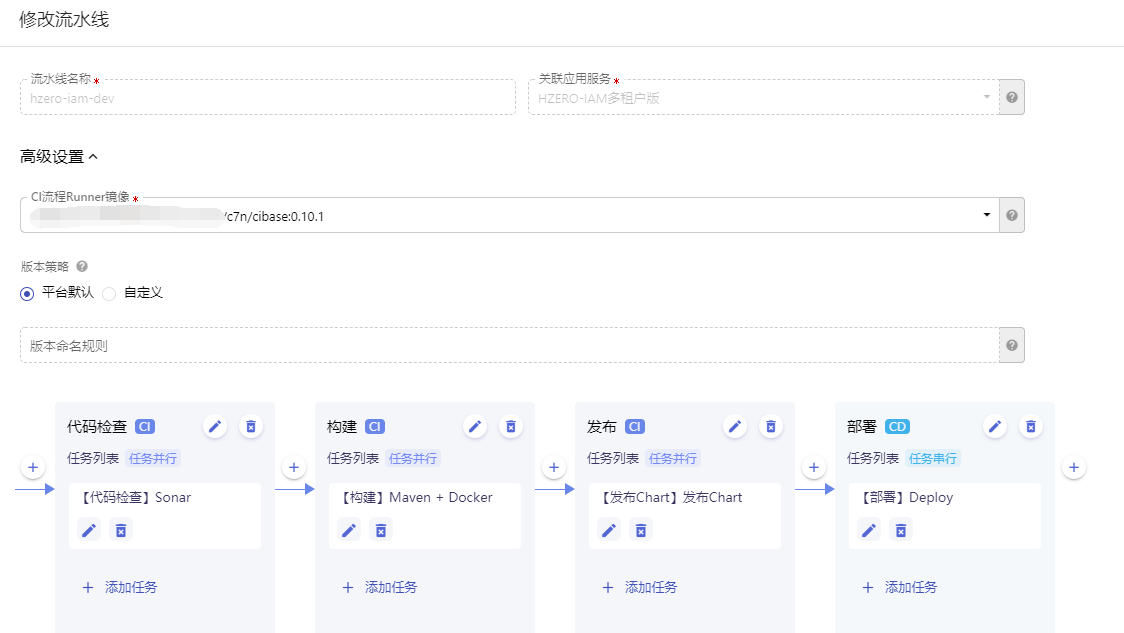
创建应用流水线
功能路径:开发 > 应用流水线
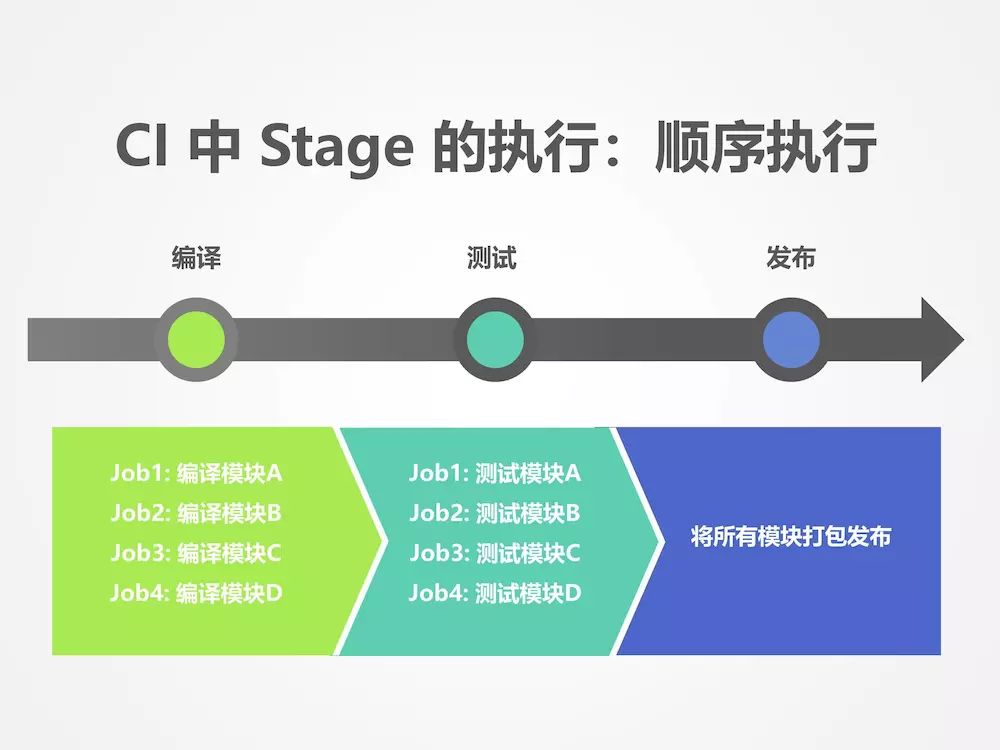
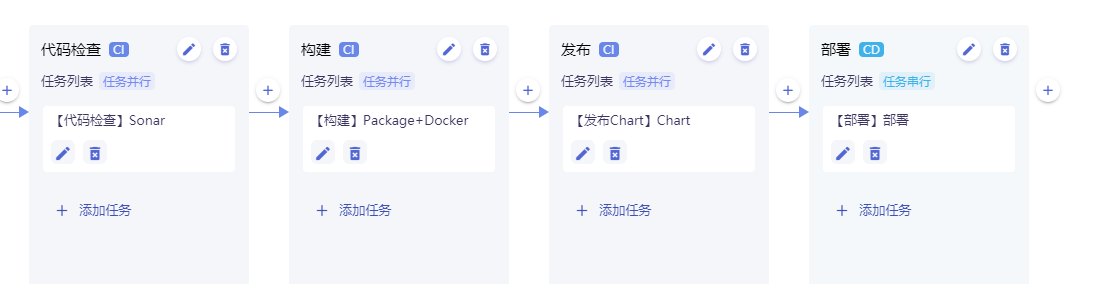
在应用流水线中创建流水线,基本的流程至少需要包含构建、发布和部署三个流程,代码检查是可选的部分。
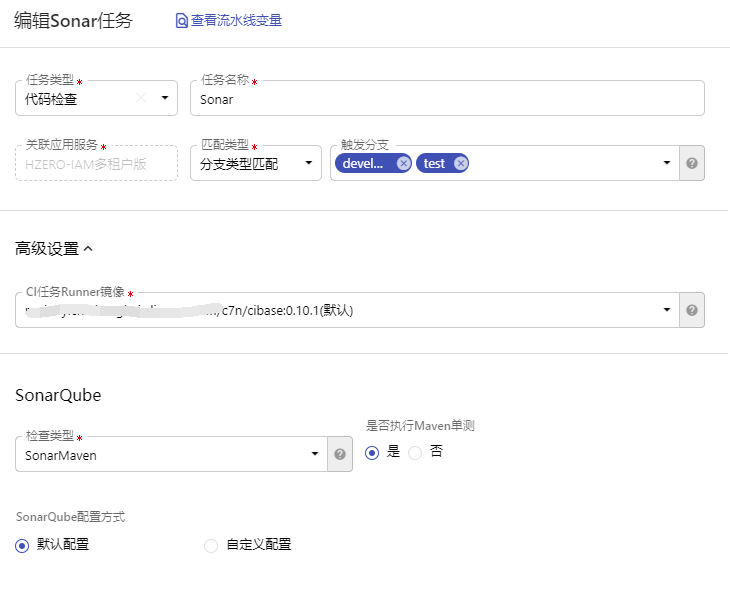
代码检查配置
选择需要检查的代码分支,检查类型分为两类,SonarMaven用来检查Maven项目,SonarScanner用来检查通用项目,自定义配置用来配置私有的Sonar服务信息。
构建配置
构建这一步主要执行Maven编译打包和Docker镜像构建,共享目录设置定义是否使用缓存,比如历史拉取的Maven资源等等。
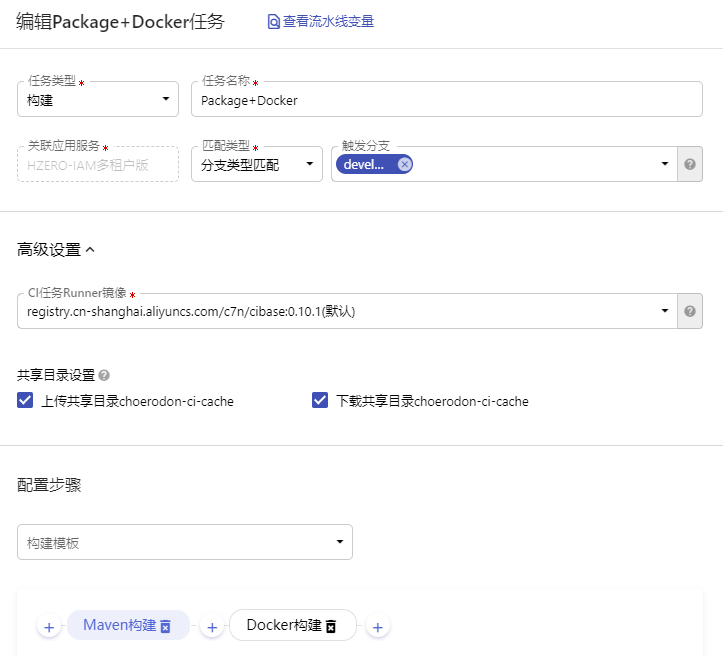
Maven构建这一步,没有特殊需要,一般只需要执行
mvn package -Dmaven.test.skip=true -U -B
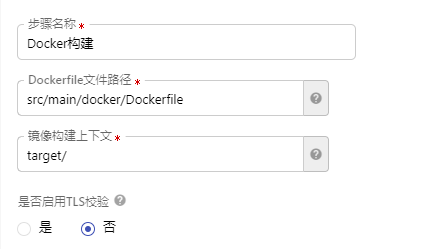
Docker构建这一步需要配置一些文件路径,Dockerfile文件路径需要填写文件的相对路径,镜像构建上下文是执行镜像打包命令的目录,一般是构建产物所在的目录,例如Maven默认构建的包所在的目录为target目录,这里填写的是构建产出物的相对路径。
生效“应用流水线”
在上一步创建完应用流水线之后,如下所示:
注意:如果你的目标分支不是master,还需要做一些手工处理,需要手工将master分支的.gitlab-ci.yml文件复制或者合并到目标分支。
测试自动化部署
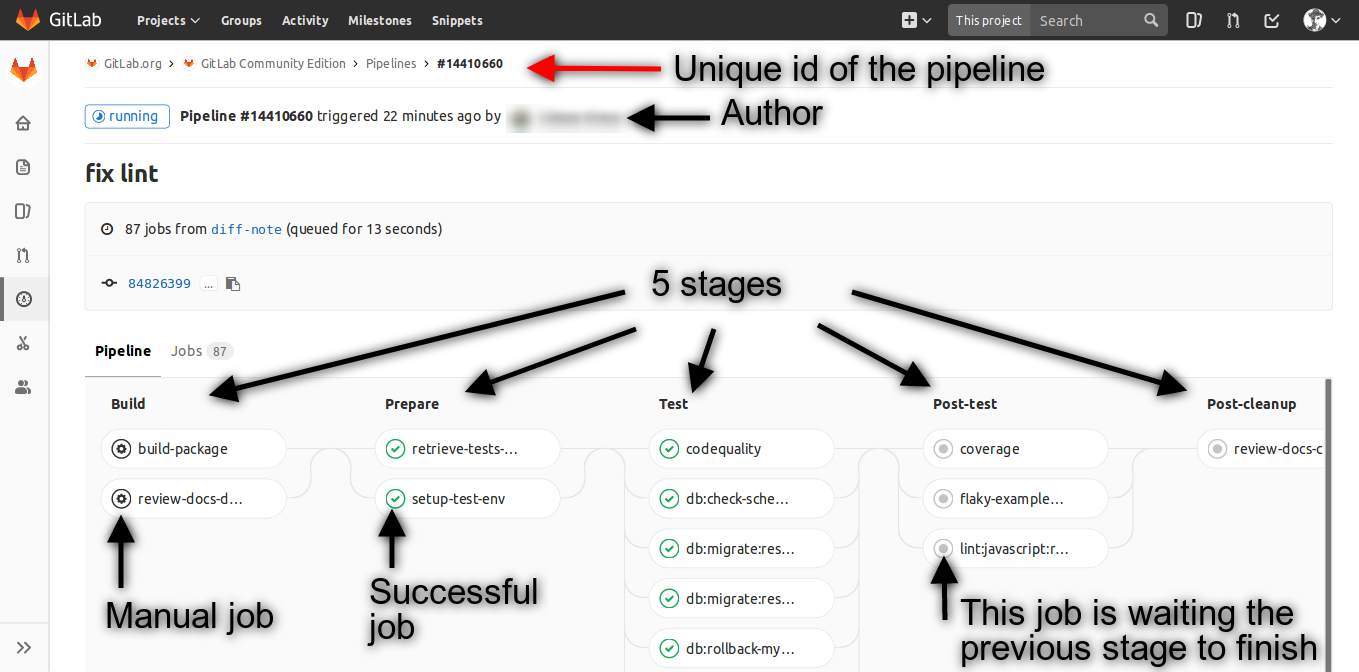
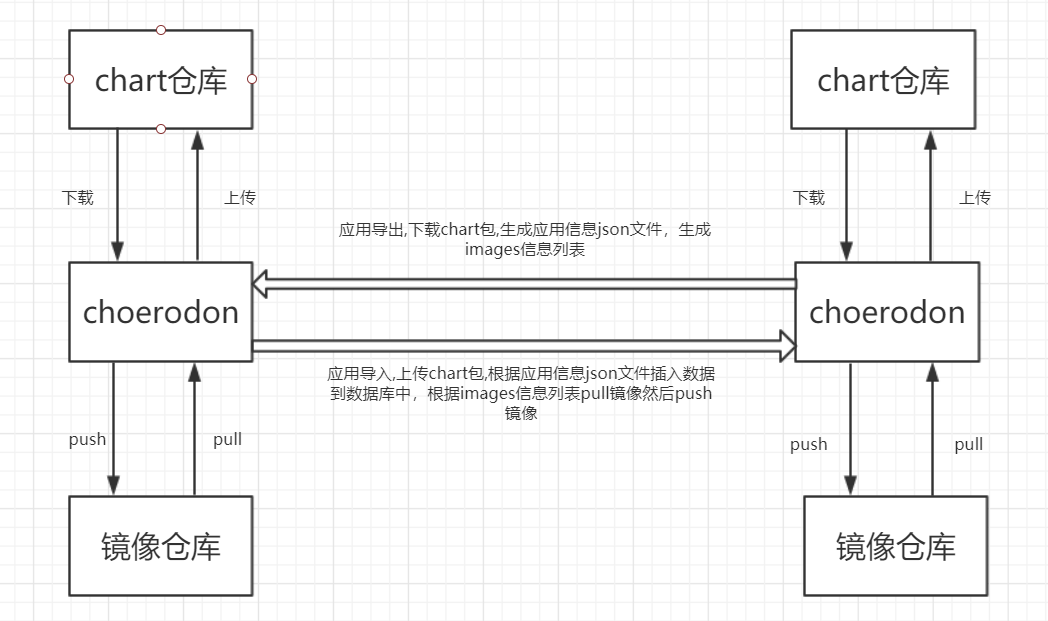
完成所有配置之后,在项目中提交代码或者直接在应用流水线中选择全新执行,然后在猪齿鱼的应用流水线中和 Gitlab 的CI/CD > Pipelines中可以看到编译和镜像打包步骤的执行。
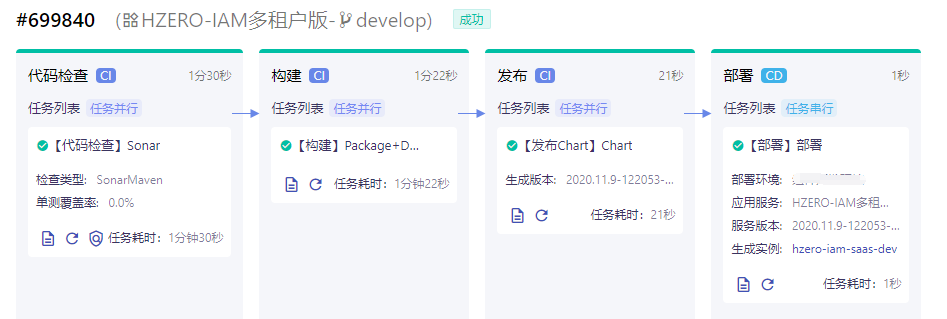
在部署节点执行完成之后,在部署 > 应用部署 > 资源中查看相关的服务可以看到实例的替换。
触发器部署
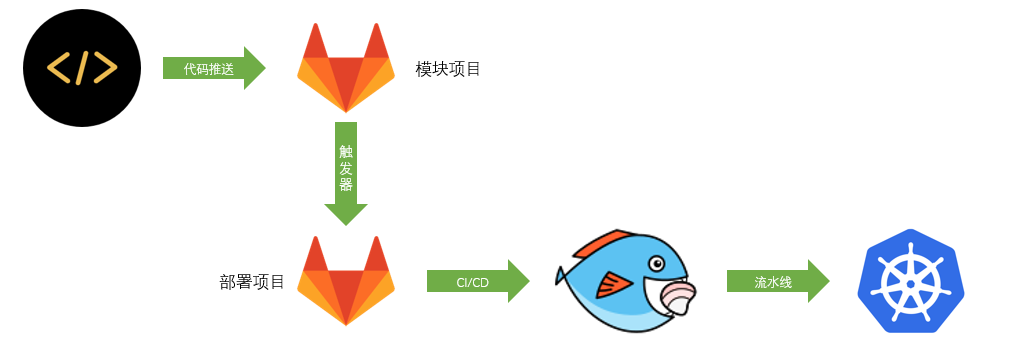
在实际项目开发过程中,可能存在部分基础组件项目,这些项目不会直接部署到服务器,而是需要打包成可以来的Jar到Maven仓库中,然后再部署依赖了此模块的项目,为了解决这类的需求,需要借助Gitlab的触发器来实现。
创建触发器
如果项目依赖了其他的模块,需要在模块代码更新之后自动部署,可以在Gitlab中创建触发器。
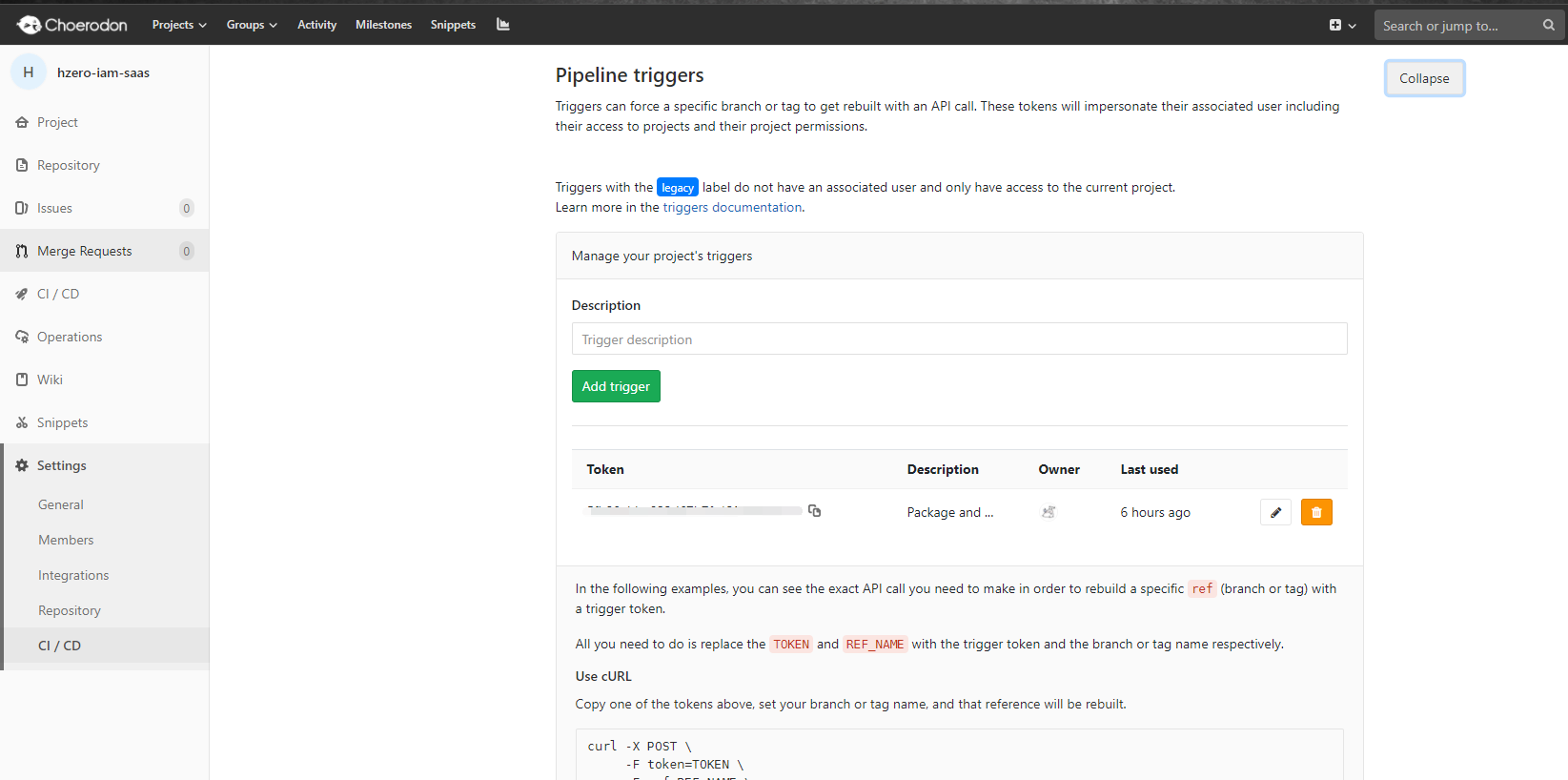
触发触发器
新建好触发器之后,复制下方提示中的脚本到被依赖模块项目的应用流水线的自定义阶段。
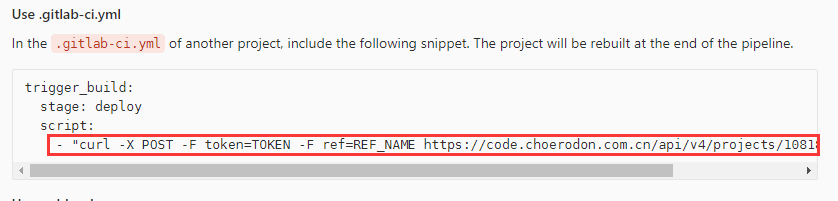
自定义CI配置:
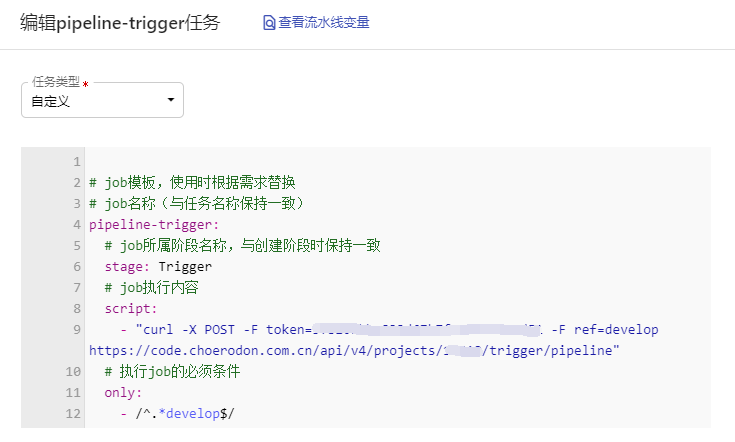
如果需要将当前工程部署到Maven仓库供其他项目拉取,在CI的Maven构建步骤中选择自定义仓库配置

然后执行打包命令
mvn clean deploy -Dmaven.test.skip=true -Dmaven.springboot.skip=true -Dmaven.javadoc.skip=true -U -B -s settings.xml
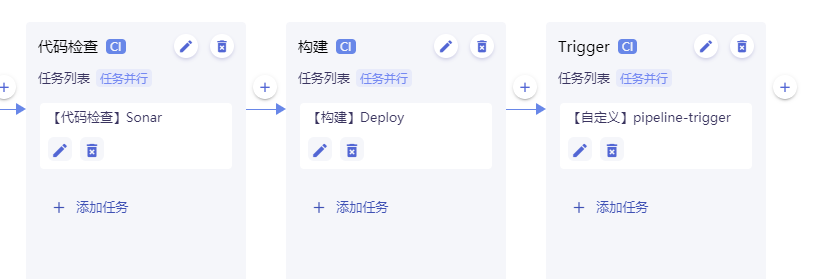
完整的应用流水线配置如下所示:
关于猪齿鱼
Choerodon 猪齿鱼作为全场景效能平台,是基于Kubernetes,Istio,knative,Gitlab,Spring Cloud来实现本地和云端环境的集成,实现企业多云/混合云应用环境的一致性。平台通过提供精益敏捷、持续交付、容器环境、微服务、DevOps等能力来帮助组织团队来完成软件的生命周期管理,从而更快、更频繁地交付更稳定的软件。
更多内容
大家可以通过以下社区途径了解Choerodon猪齿鱼文档、最新动态、产品特性:
【Choerodon官网】
【汉得开放平台】
【汉得开放论坛】
https://openforum.hand-china.com/
也可加入Choerodon猪齿鱼官方社区用户交流群,交流猪齿鱼使用心得、Docker、微服务、K8S、敏捷管理等相关理论实践心得,群同步更新版本更新等信息,大家可以加群讨论交流。
①-Choerodon猪齿鱼官方交流(已满);
②-Choerodon猪齿鱼官方交流(可加);【微信号发至客服邮箱[email protected],运营小伙伴拉您入官方交流群】
欢迎加入Choerodon猪齿鱼社区,共同为企业数字化服务打造一个开放的生态平台。