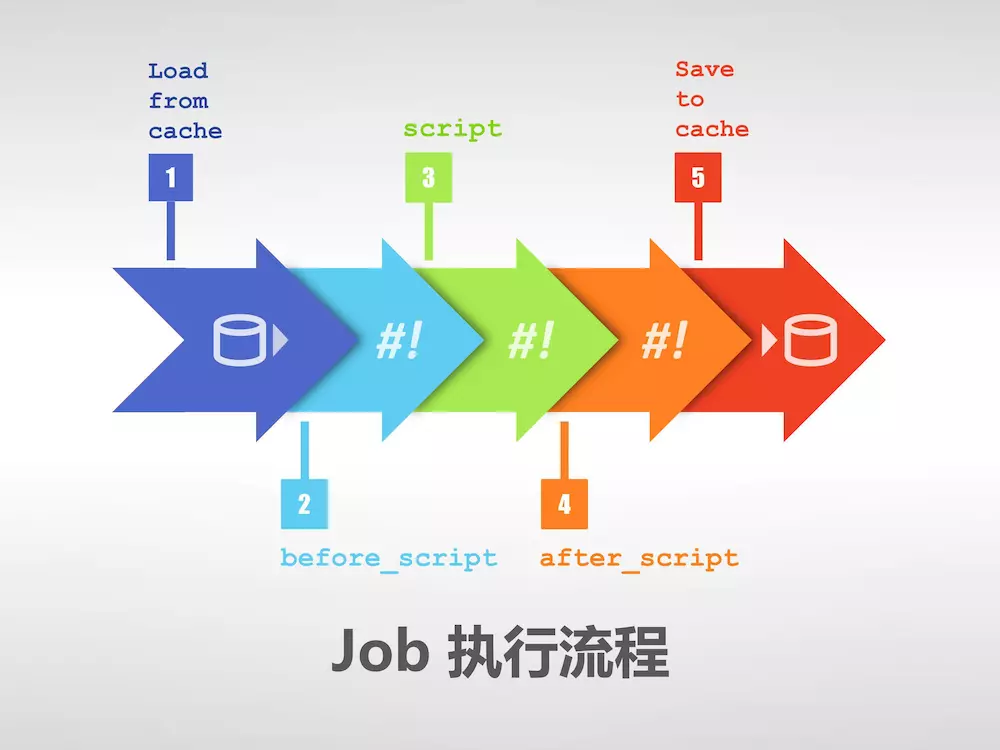
Choerodon猪齿鱼平台使用微服务架构进行开发,部署在Kubernetes 扩展中,并且服务新功能开发完成后会被依次部署到暂存环境测试,UAT 环境验收和生产环境使用。在这多个环境的部署过程中,猪齿鱼平台只需要一次CI生成的包,便能实现服务部署的“因地制宜”。
需求
猪齿鱼平台集成的GitLab用于进行CI的过程,在微服务程序中经过Gitlab CI的docker_build和chart_build步骤之后,对应一次成功的CI过程,会有一个可以进行部署的Helm的发行包。
一般情况下,不同环境下基础设施如数据库的地址是不同。而部署服务的需求是一次打包生成的安装包可以在不同的环境进行部署而不需要对源代码重新打包。
spring:
datasource:
url: "jdbc:mysql://localhost/demo_service?useUnicode=true&characterEncoding=utf-8&useSSL=false" # 本地数据库
username: demo
password: demo
方案基础
猪齿鱼微服务后端环境变量方案的本质上是Springboot的环境变量机制和头盔环境变量机制的结合。
所以在此之前,先聊一聊SpringBoot 和头盔所提供的支持。
SpringBoot环境变量支持
SpringBoot支持外部化配置,允许使用者通过属性文件,YAML文件,环境变量及命令行参数对服务进行外部化配置。同时允许 @Value和@ConfigurationProperties注解的方式对上述变量进行访问。
@Value方式:
@Value("${JAVA_HOME}")
private String javaHome;
@Value("${spring.application.name}")
private String appName;
@ConfigurationProperties 方式:
@Component
@ConfigurationProperties(prefix = "services.gitlab")
public class GitlabConfigurationProperties {
private String password;
private Integer projectLimit;
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
public Integer getProjectLimit() {
return projectLimit;
}
public void setProjectLimit(Integer projectLimit) {
this.projectLimit = projectLimit;
}
}
在SpringBoot官方文档中,SpringBoot提供了多于十种配置环境变量的方式,并列出他们所配置的环境变量的优先级。从文档中可以看到,对于应用程序而言,系统环境变量的优先级高于应用内的配置文件所配置的值。
Helm环境变量支持
在猪齿鱼微服务中,项目根目录下会有一个 chart 目录用于定义此服务如何打包成 Helm Chart 包,这个目录下就是 helm 的 chart 文件结构:
devops-service/
Chart.yaml # 包含关于chart的的信息的YAML文件
LICENSE # 可选:包含chart的许可证信息的纯文本文件
README.md # 可选:chart的README文件
requirements.yaml # 可选:列出依赖信息的YAML文件
values.yaml # 这个chart的默认配置值
charts/ # 包含这个chart所依赖的多个chart
templates/ # 这个目录下包含了多个模板文件以结合配置值生成有效的Kubernetes manifest文件
templates/NOTES.txt # 可选:包含简短使用提示的纯文本文件
更多关于chart下文件的信息,可点击这里
Helm的模板文件主要是使用 Go Template Language 以及一些其他补充函数。所有的模板文件存在于 templates 目录下,在helm对chart包进行渲染的时候,模板所用到的配置值会有两个来源:chart包内的values.yaml和Chart.yaml文件及命令行提供的配置值。
chart包内提供的配置值:
.Release # 和release相关的一些属性值,如当前部署的release的名称,命名空间
.Files # 一个包含其它没有被指定(未被上文提到的)的文件的map结构,可以用于访问其它文件内的内容
.Chart # 访问 Chart.yaml 文件中的一些值,只能访问这个文件预定义的值,其它值会被忽视
.Values # 访问 Values.yaml 文件中定义的配置值
更过关于预定义变量的文档,可点击这里
命令行提供的配置值:
# 命令行直接指定配置值的方式,--set:
$ helm install nginx --repo localhost --name nginx-release-zmf --set deployment.name=zmf-naginx-dep
# 命令行使用--values指定values.yaml文件的方式
# 在命令行的配置文件名称可以不为values.yaml
# 命令行指定的文件会和chart包内的values.yaml文件合并
# 且会覆盖values.yaml内同名配置项的值
# 如下:
$ helm install nginx --repo localhost --values=myvals.yaml
在模板文件中使用模板文件定义的语法和内置函数可以访问到以上所提供的配置值,下列是一个Kubernetes Deployment文件的模板示例:
apiVersion: apps/v1beta2
kind: Deployment
metadata:
name: {{ .Values.deployment.name }}
labels:
app.kubernetes.io/name: {{ .Values.deployment.name }}
helm.sh/chart: {{ include "nginx.chart" . }}
app.kubernetes.io/instance: {{ .Release.Name }}
app.kubernetes.io/managed-by: {{ .Release.Service }}
spec:
replicas: {{ .Values.replicaCount }}
selector:
matchLabels:
app.kubernetes.io/name: {{ .Values.deployment.name }}
app.kubernetes.io/instance: {{ .Release.Name }}
template:
metadata:
labels:
app.kubernetes.io/name: {{ .Values.deployment.name }}
app.kubernetes.io/instance: {{ .Release.Name }}
spec:
containers:
- name: {{ .Chart.Name }}
image: "{{ .Values.image.repository }}:{{ .Values.image.tag }}"
imagePullPolicy: {{ .Values.image.pullPolicy }}
env:
{{- range $name, $value := .Values.env.open }}
{{- if not (empty $value) }}
- name: {{ $name | quote }}
value: {{ $value | quote }}
{{- end }}
{{- end }}
ports:
- name: http
containerPort: 80
protocol: TCP
livenessProbe:
httpGet:
path: /
port: http
readinessProbe:
httpGet:
path: /
port: http
resources:
{{ toYaml .Values.resources | indent 12 }}
{{- with .Values.nodeSelector }}
nodeSelector:
{{ toYaml . | indent 8 }}
{{- end }}
{{- with .Values.affinity }}
affinity:
{{ toYaml . | indent 8 }}
{{- end }}
{{- with .Values.tolerations }}
tolerations:
{{ toYaml . | indent 8 }}
{{- end }}
在模板文件中可以使用 {{ .Value.property.name }} 的方式直接访问配置值。
使用模板文件的方式可以使得 Helm 根据命令传入的参数渲染chart包以部署在不同的环境中。
更多的的模板语法,可点击这里
方案实现
在重温SpringBoot和Helm提供的环境变量方案之后,再来详细看看猪齿鱼微服务是怎么将它们结合的。
此处以devops-service的0.18.0版本为例, 说明这个过程。
猪齿鱼微服务的打包
打包过程分为三步:
- maven 打包 SpringBoot 项目为 JAR 包。在项目被打包生成JAR包后,JAR包中实际上只有 bootstrap.yml 和 application.yml 两个配置文件,也可以说只有一份配置文件,猪齿鱼微服务后端并没有采用多种配置文件进行切换的方式。resources文件夹下内容如下:
- docker 根据项目根目录下docker目录下的配置生成包含 JAR 包的镜像文件。

- helm 从源代码中的chart目录下的文件夹(在下图中是devops-service目录)生成 chart 包。
在打包的步骤结束后,一个可以在Kubernetes集群中进行部署Helm Release就出炉了。
注:以上目录结构由根目录下的 .gitlab-ci.yml所定义。
猪齿鱼微服务环境变量的设置过程
在/chart/devops-service/values.yaml文件中,有一部分如下图所示:

这里定义了一部分由 env.open开头的配置项。
在/chart/devops-service/templates/deployment.yaml文件中,有一部分如下图所示:

在图中的第26行,通过模板的语法访问了 values.yaml文件中定义的 env.open 的值,而range函数是将 env.open 所代表的 map的键值对赋值到 name 和 value 中,并且在内层判断 value 不为空就为模板添加 28 行和29 行所示的结构。
结合文件中上下文,可以发现,这是在Kubernetes的对象文件中,定义docker容器的环境变量的位置。也就是说,这里通过模板语法读取helm所提供的配置值,定义kubernetes中部署的Deployment中的容器的系统变量值。而猪齿鱼的微服务最终是通过helm部署helm release而运行在Kubernetes的容器中的,此时运行在容器中的SpringBoot应用就能够读取到系统环境变量,由于上文提到的SpringBoot配置项优先级的关系,系统环境变量会覆盖 JAR 包内默认提供的值。
所以,在猪齿鱼微服务打包完成之后,即可使用helm install或者 helm upgrade命令在命令行传入根据环境所配置的values以部署同一个服务于不同的环境中。
最后,再来一起回顾一下整个过程:
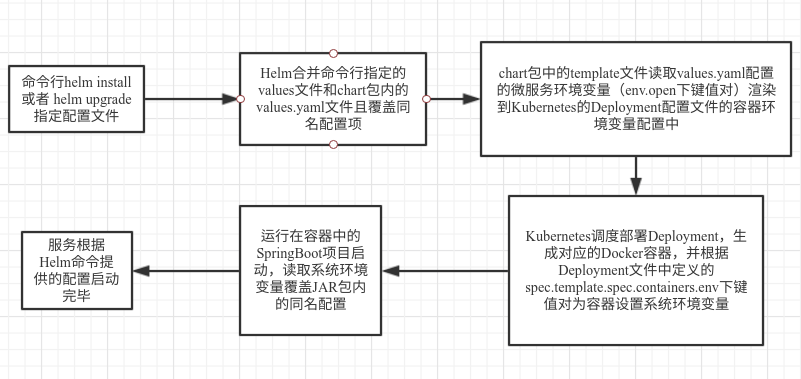
从方案看猪齿鱼平台实现多环境部署
在理解猪齿鱼如何实现后端一次打包生成的包,可以多环境部署之后,再看看猪齿鱼平台如何运用这个方案实现这个多环境部署的过程。
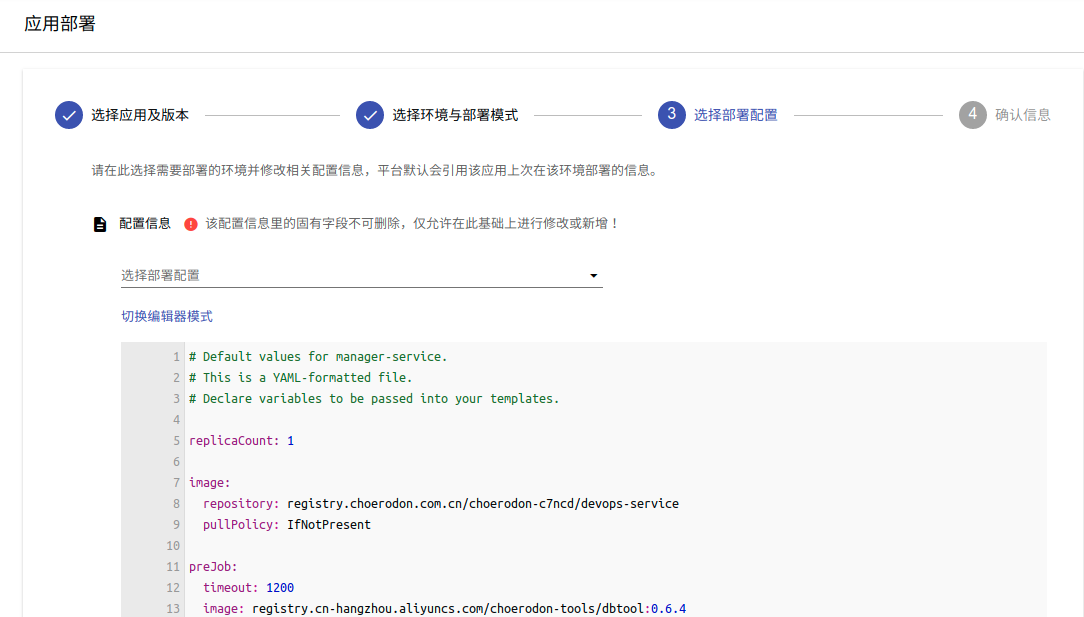
第一步:猪齿鱼平台使用者选择一个服务的版本,根据所需部署的环境,填写对应的values进行部署:
第二步:猪齿鱼平台的 devops-service 收到请求后对参数进行校验,异步处理部署请求,为部署的一个release在环境对应的GitLab仓库中生成一个release开头的文件,这个文件中存储这次部署的所对应的版本信息、名称信息以及values值。
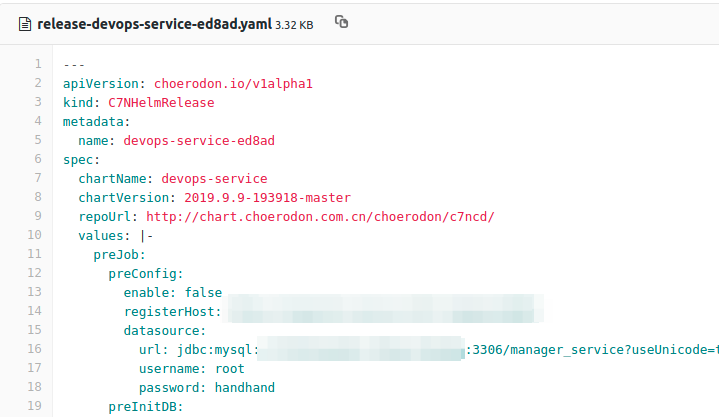
第三步:choerodon-agent会去拉取环境库解析文件,并根据文件的新增或更新在Kubernetes集群执行对应的helm install或helm upgrade操作。
经过以上三步,猪齿鱼平台的使用者部署或升级的实例会在对应的Kubernetes集群中安装或升级。
至此,猪齿鱼平台支持一个服务在多个环境部署的实现方式也就理清了。
更多关于猪齿鱼平台GitOps运用的详细情况,可阅读《Choerodon猪齿鱼 Agent——基于GitOps的云原生持续交付模型》。
更多关于Choerodon猪齿鱼的相关文章,点击蓝字阅读 ▼
关于猪齿鱼
Choerodon 猪齿鱼是一个全场景效能平台,基于 Kubernetes 的容器编排和管理能力,整合 DevOps 工具链、微服务和移动应用框架,来帮助企业实现敏捷化的应用交付和自动化的运营管理的平台,同时提供 IoT、支付、数据、智能洞察、企业应用市场等业务组件,致力帮助企业聚焦于业务,加速数字化转型。
大家也可以通过以下社区途径了解猪齿鱼的最新动态、产品特性,以及参与社区贡献: