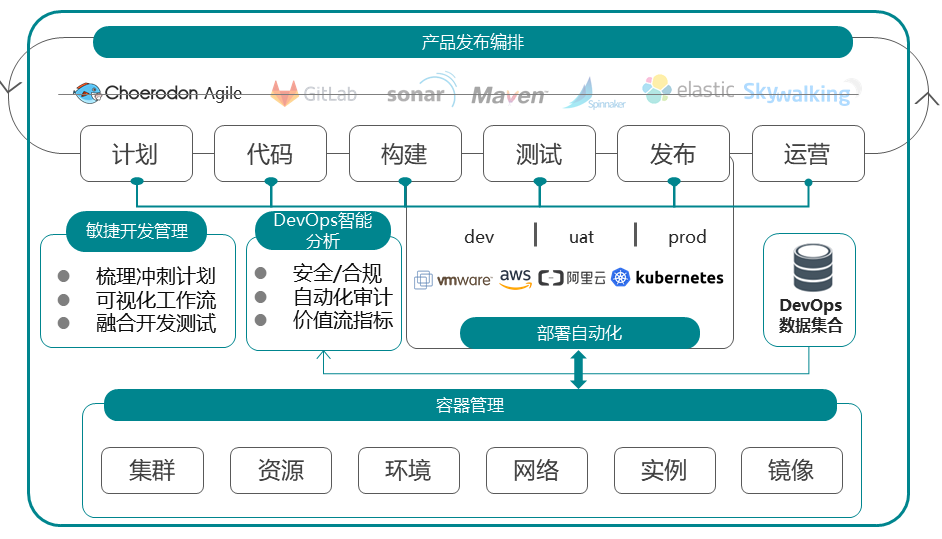
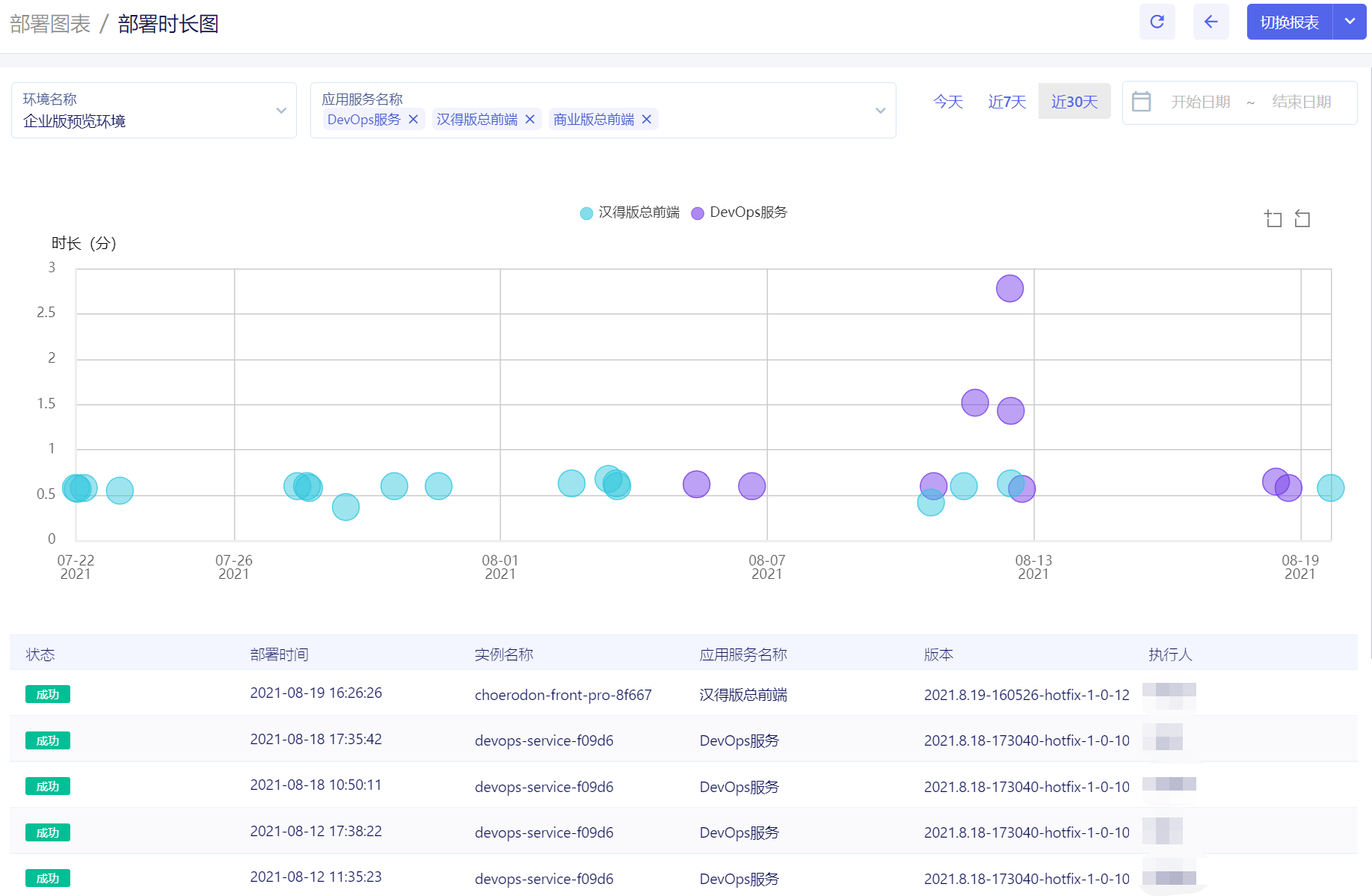
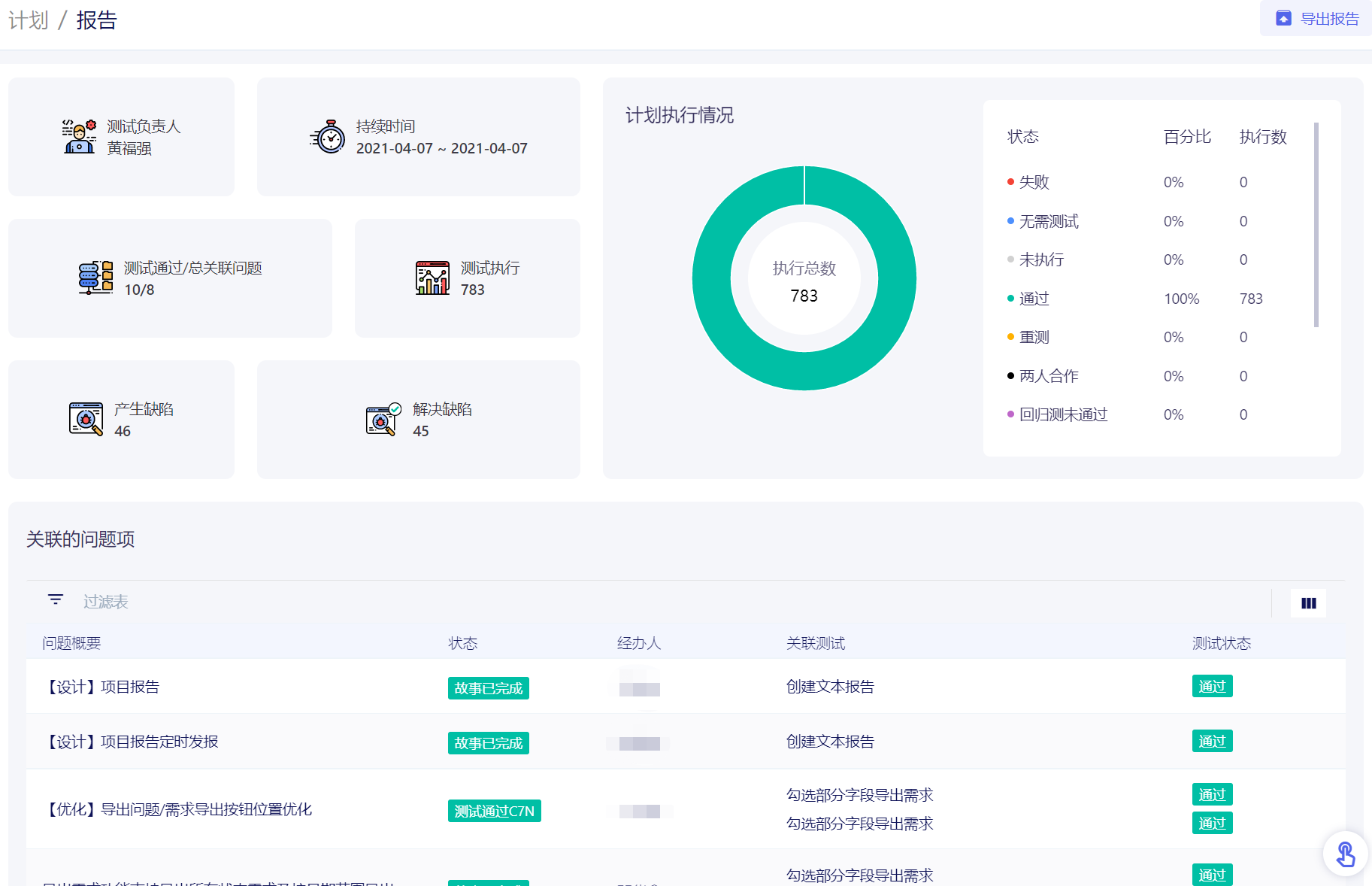
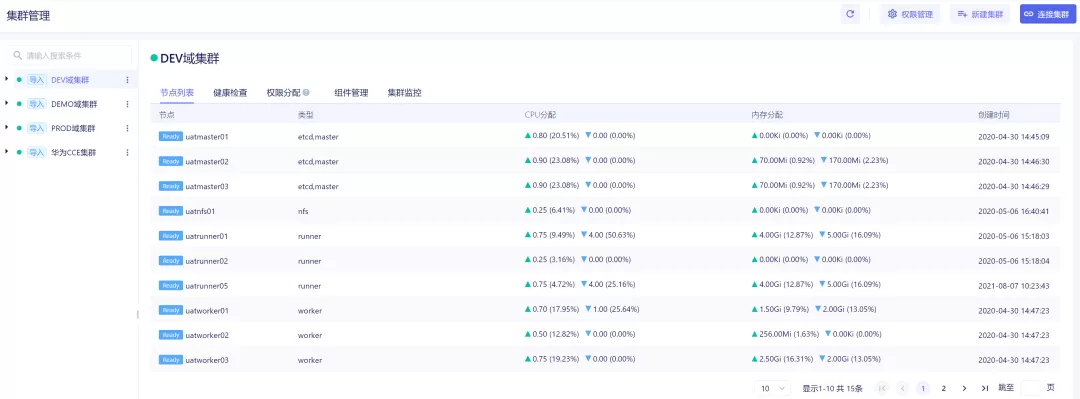
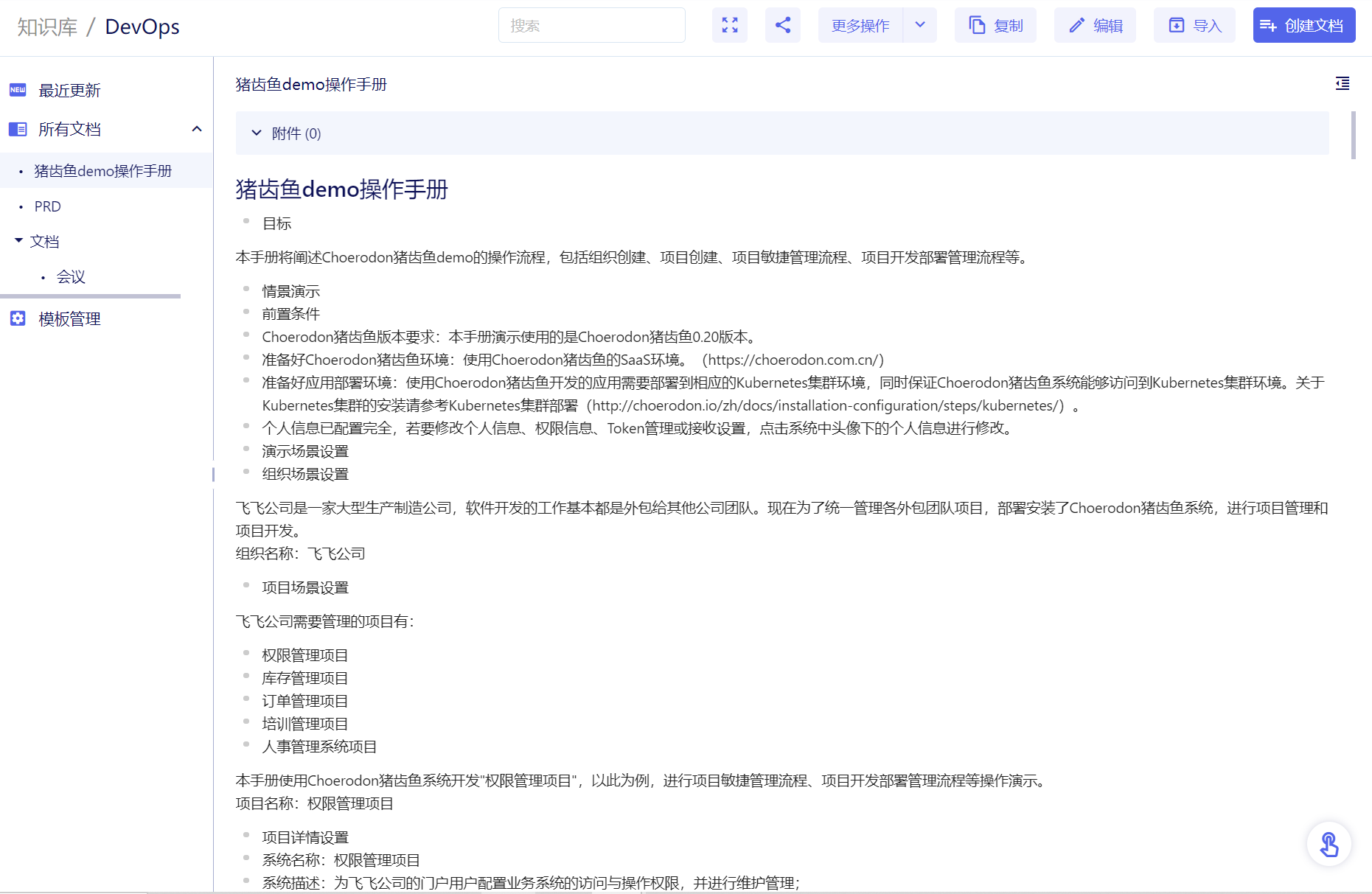
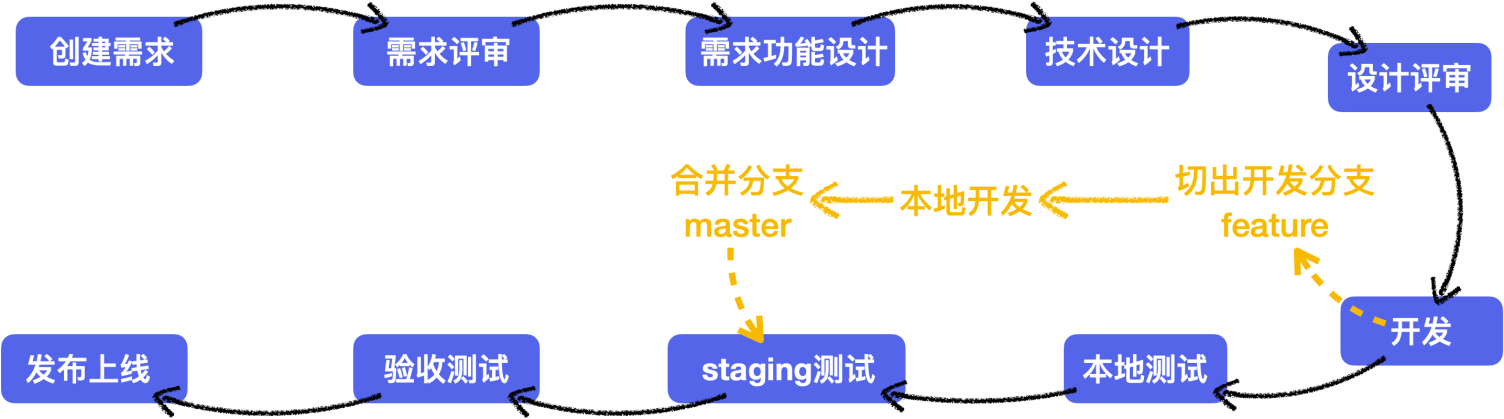
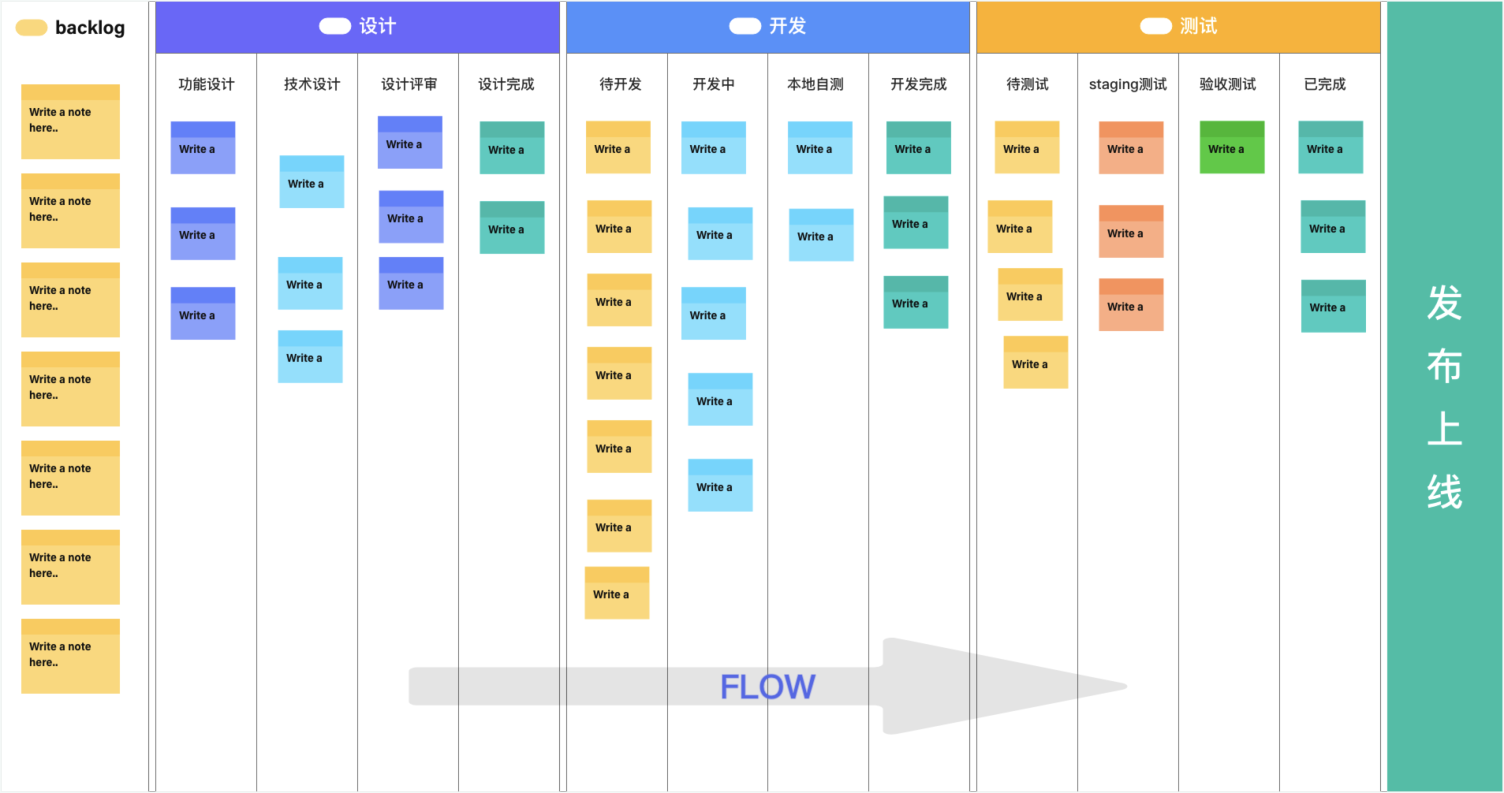
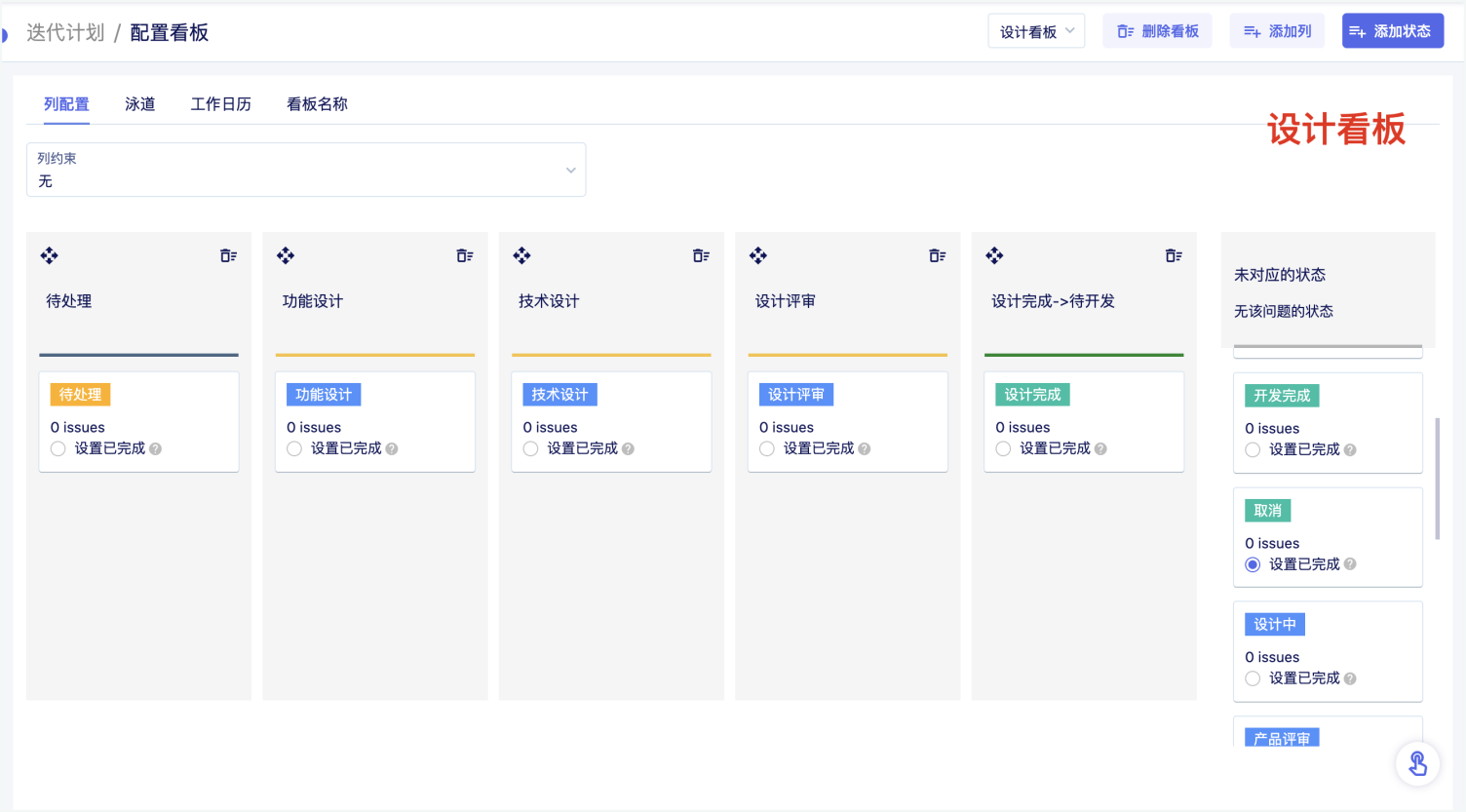
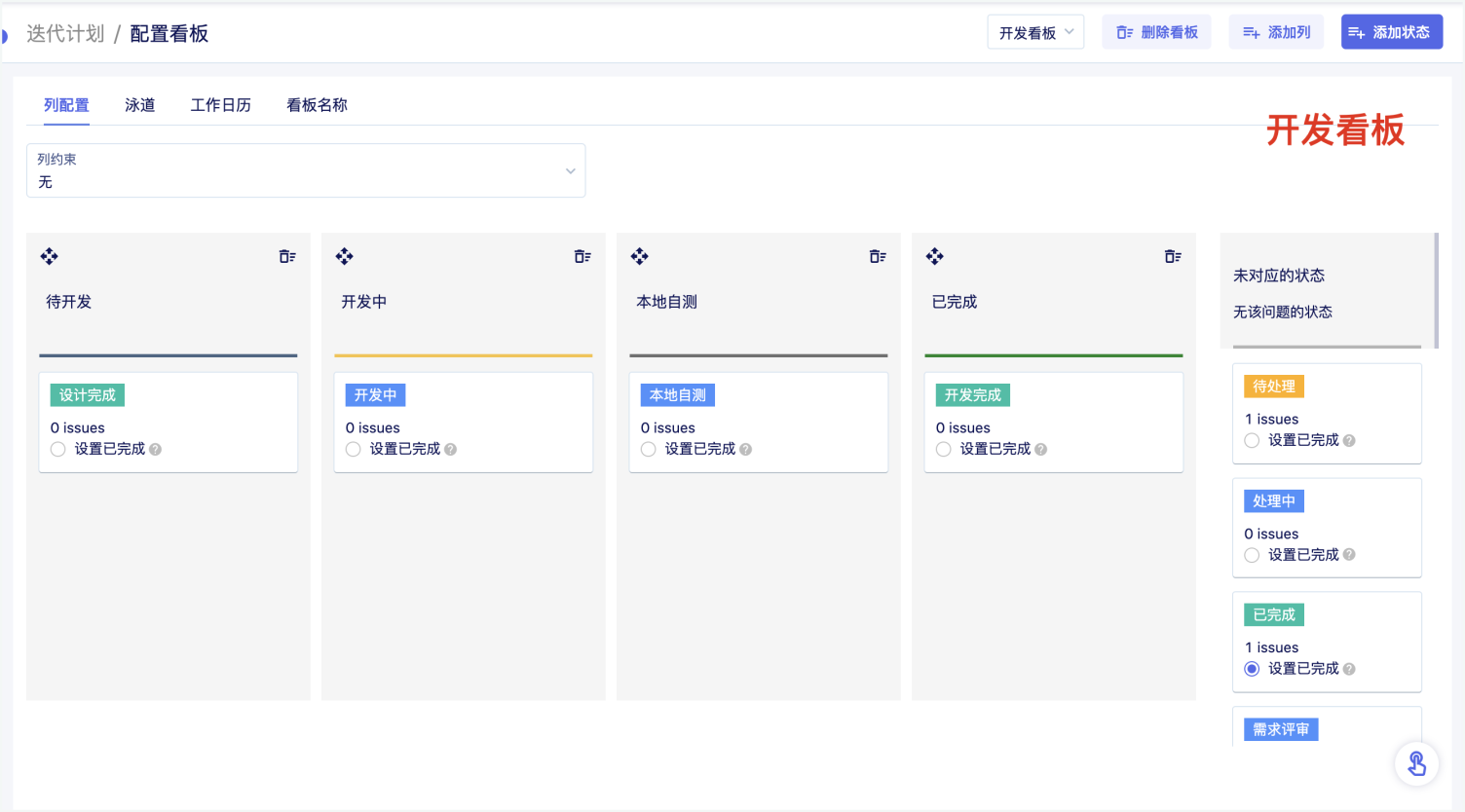
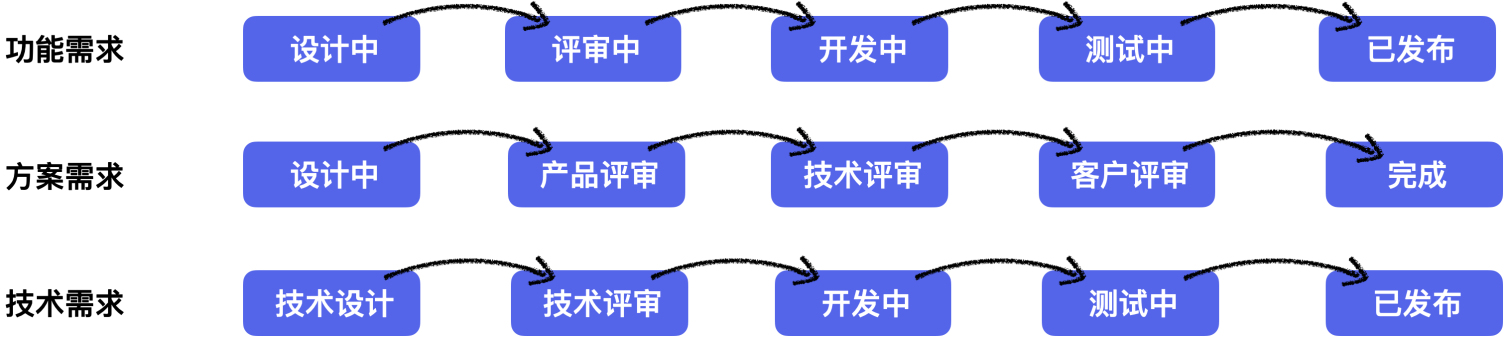
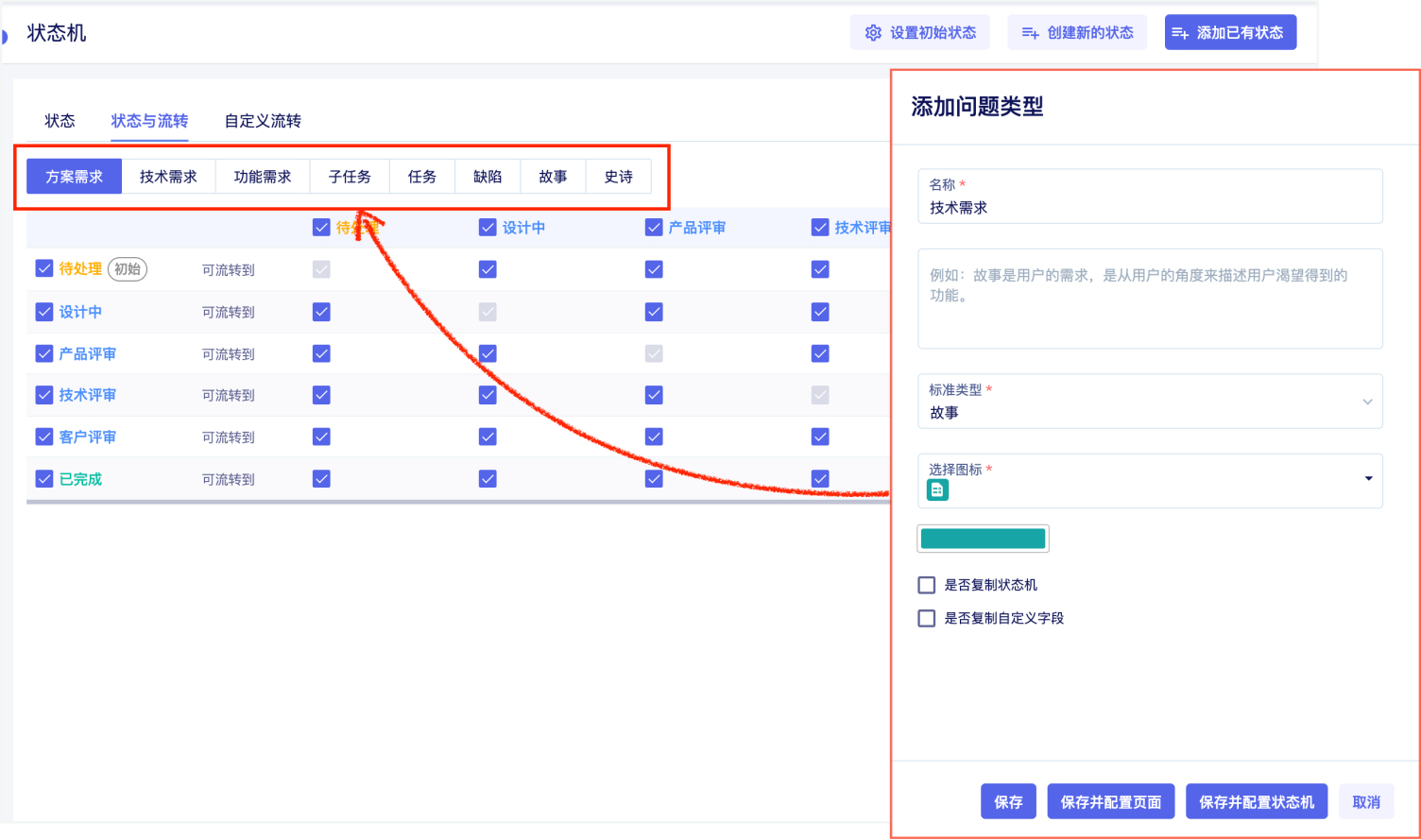
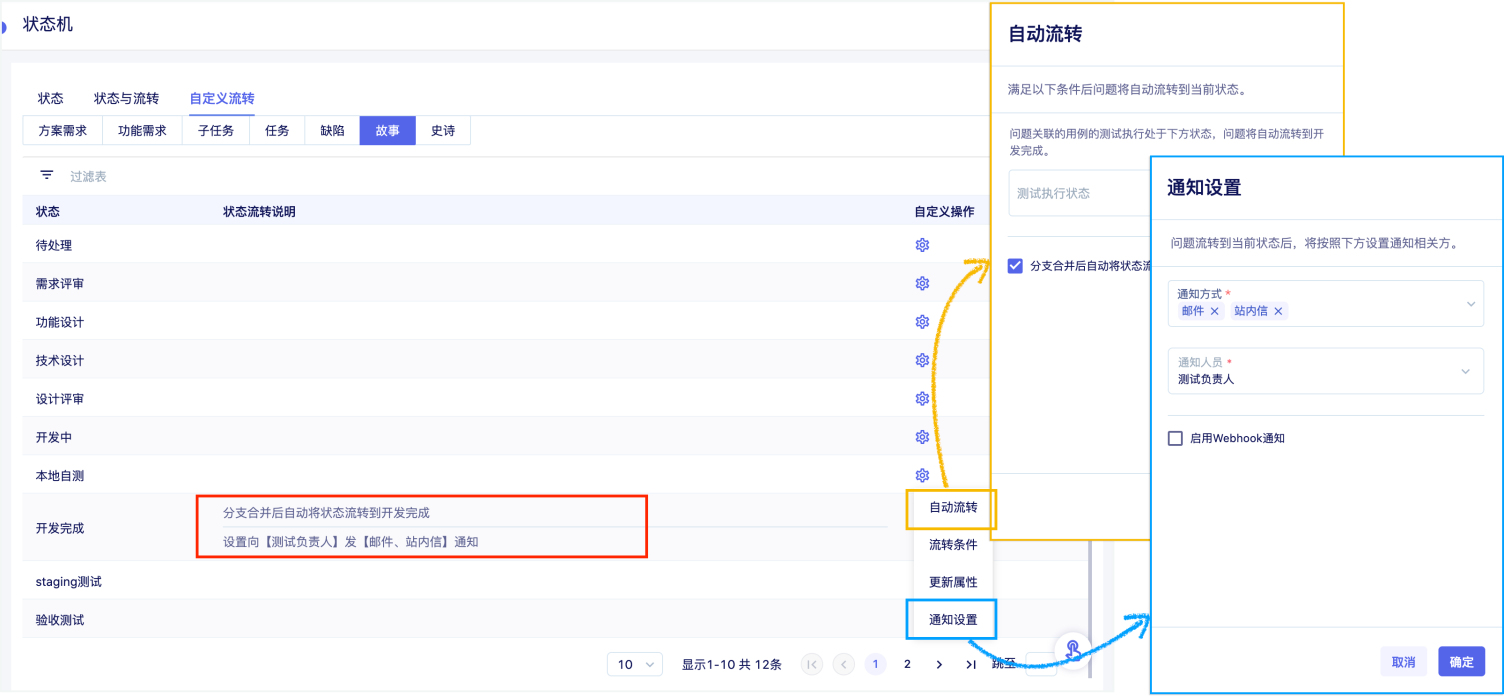
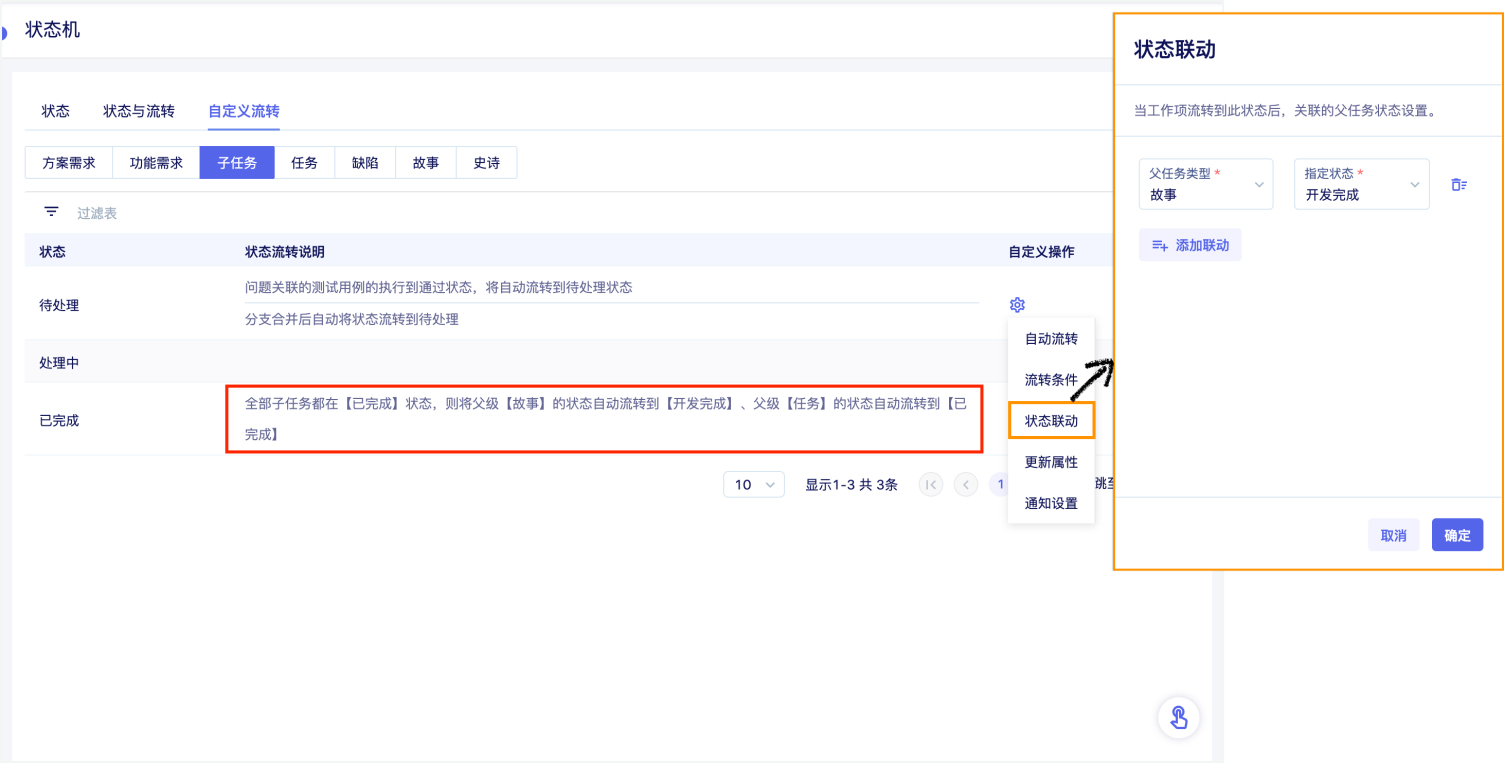
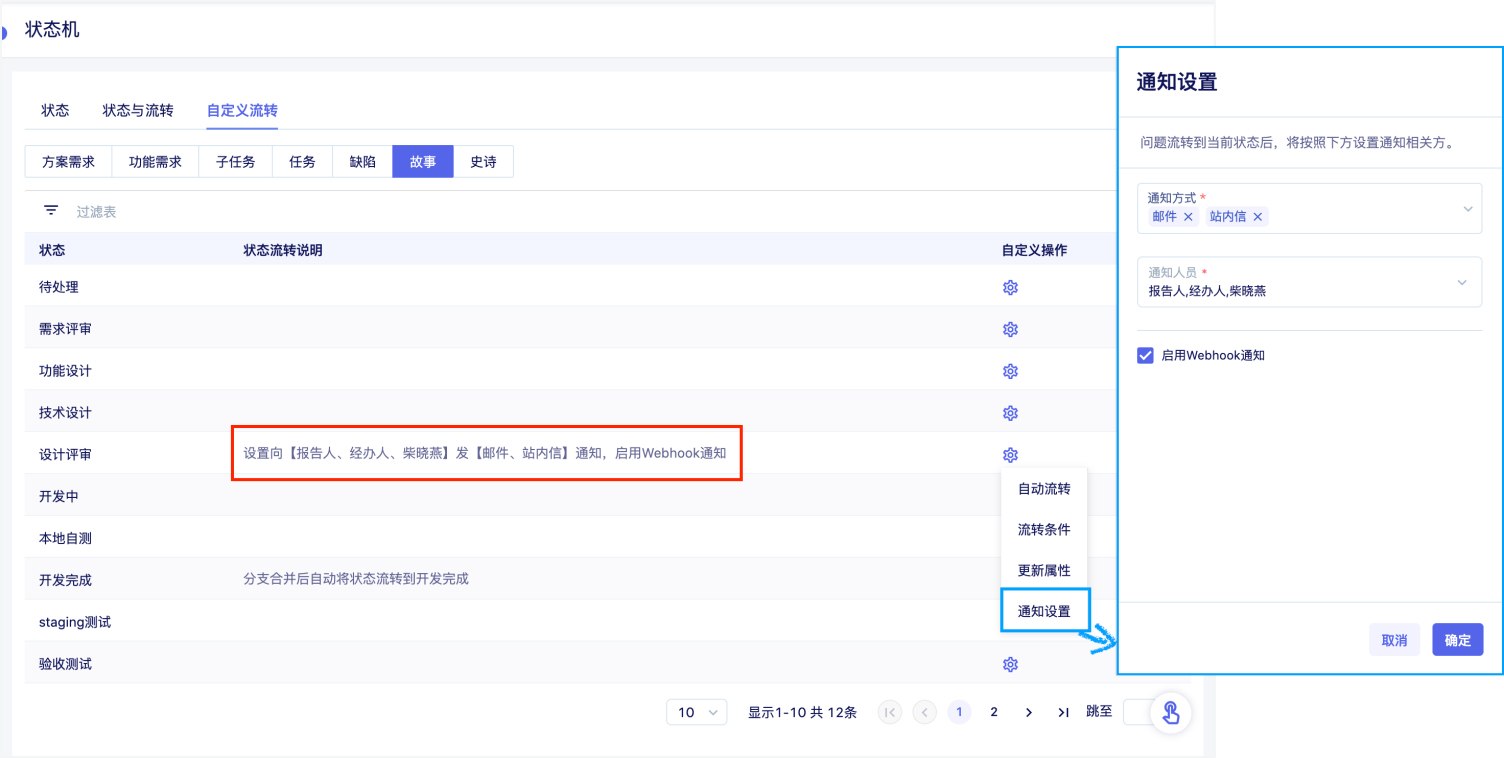
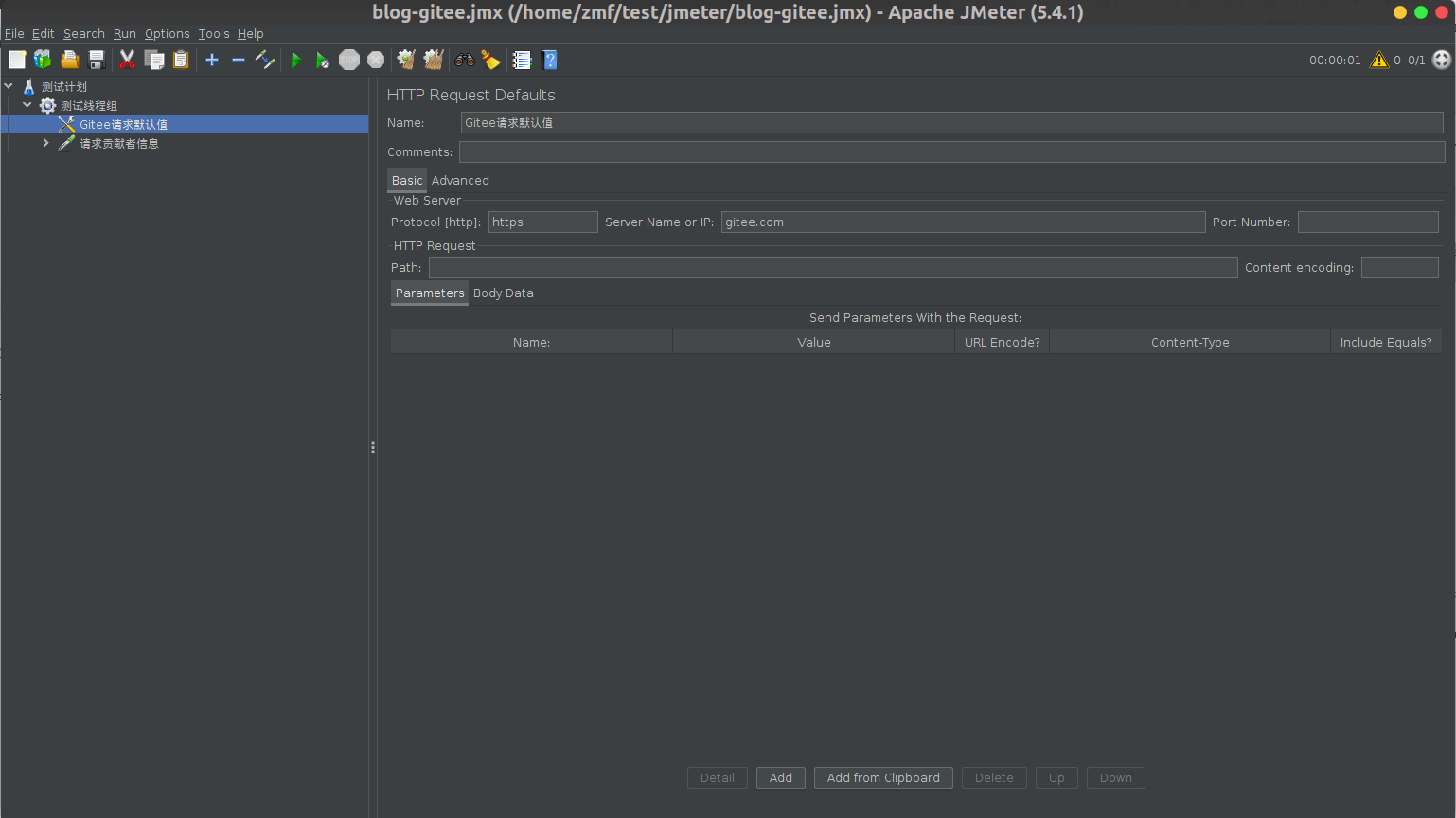
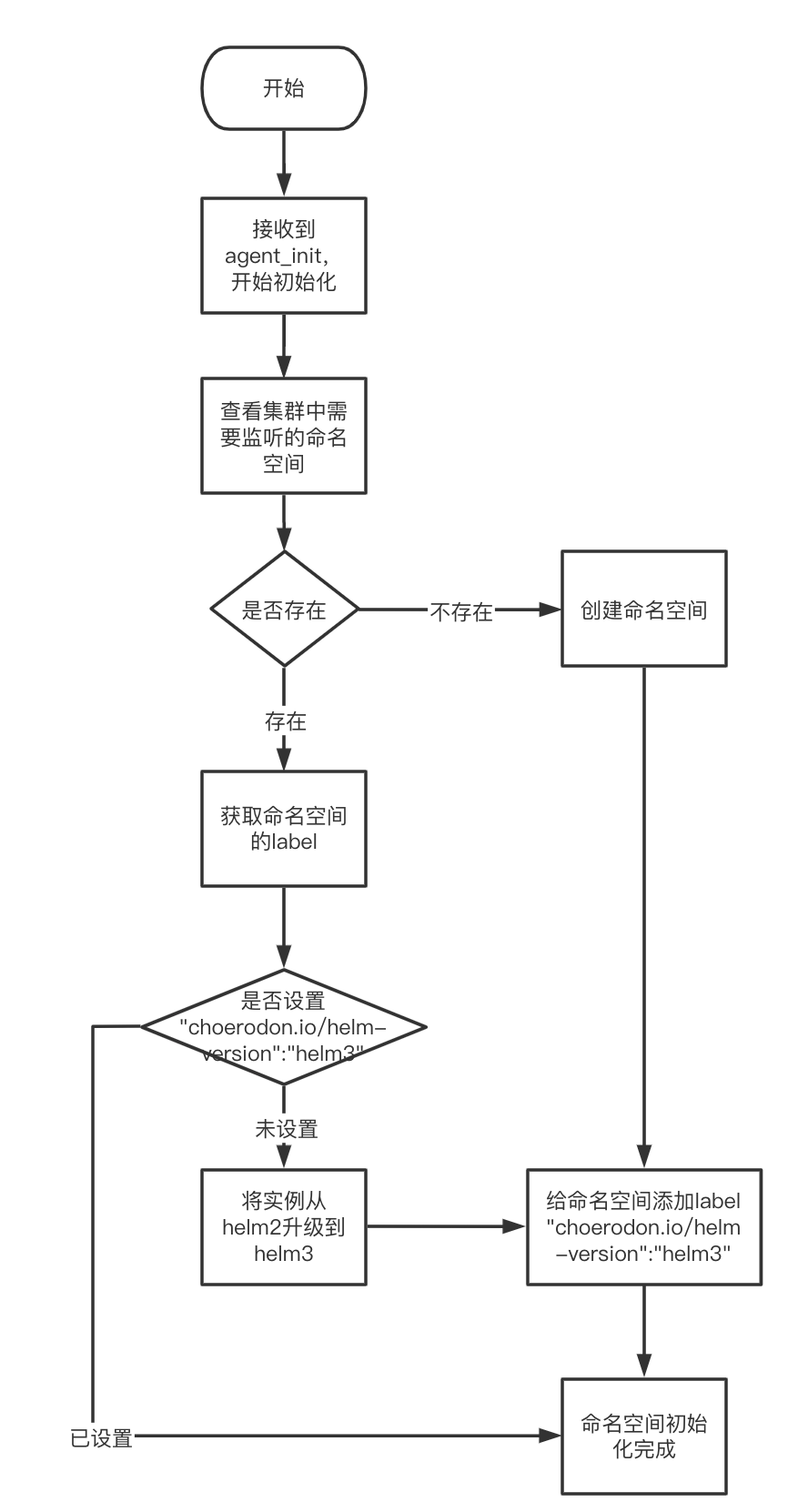
校验系统的正确性和可靠性时,仅靠用例场景无法覆盖全生产环境下的所有场景,需要一套引流工具,在系统正式上线前用线上的请求测试待上线系统,在正常请求下了解是否有报错、在数倍请求下了解系统的性能瓶颈。常用的引流工具有GoReplay、tcpcopy等。
猪齿鱼效能平台自动化测试模块流量回归测试功能,主要使用GoReplay录制产品界面中的操作产生的HTTP请求及响应用于生成流量文件,然后将其导入Choerodon平台生成用例进行管理与执行。本文通过GoReplay的介绍及GoReplay在猪齿鱼效能平台中的实践,帮助大家理解猪齿鱼流量回归测试的概念及使用。
关于GoReplay
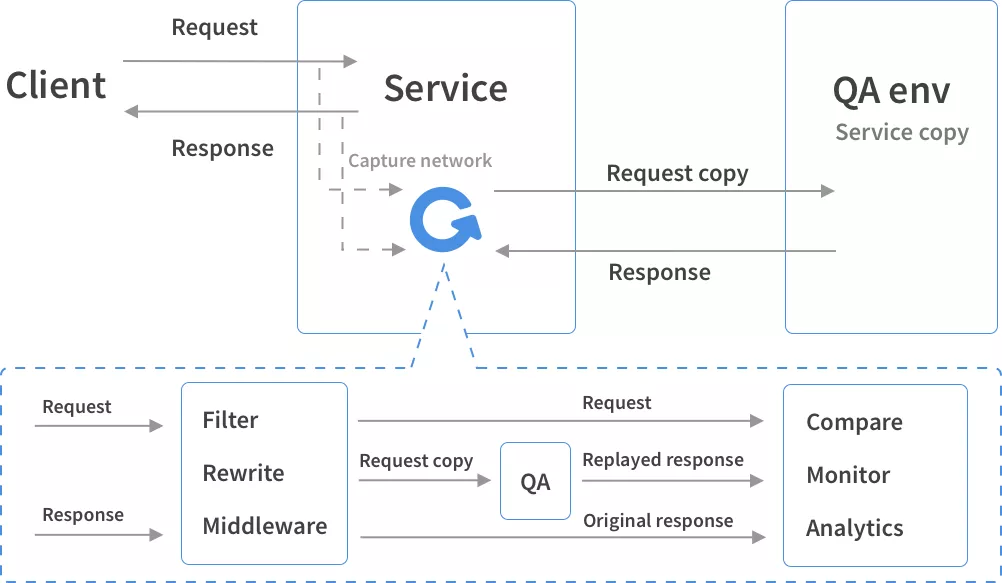
GoReplay,原名叫gor,因为其易上手,且功能比较全所以我们使用GoReplay进行流量录制。GoReplay是在投入生产之前使用真实流量测试应用程序最简单和最安全的方式。
随着应用程序的增长,测试所需的工作量也呈指数增长。GoReplay提供了重复使用现有流量进行测试的简单想法,这使得它非常强大。可以分析和记录应用程序流量,且不影响应用,消除了将第三方组件置于关键路径中带来的风险。
下载地址:https://github.com/buger/goreplay/releases
然后在环境中输入指令:
--wget https://github.com/buger/goreplay/releases/download/v1.1.0/gor_1.1.0_x64.tar.gz
这样我们就能获取到gor_1.1.0_x64.tar.gz压缩文件,。
- 然后对其解压输入指令:
--tar vxf gor_1.1.0_x64.tar.gz
文件解压过分我们得到了一个gor文件;我们将gor文件移动到path环境下,这样我们就可以使用gor命令进行流量录制了。
--input-raw - 用于捕获HTTP流量,您应该指定IP地址或接口和应用程序端口。--input-file- 接受之前使用的文件--output-file。--input-tcp - 如果您决定将来自多个转发器Gor实例的流量转发给它,则由Gor聚合实例使用。
可用输出:
--output-http - 重放HTTP流量到给定的端点,接受基础URL。
--output-file - 记录传入的流量到文件。
--output-tcp- 将传入数据转发给另一个Gor实例。
--output-stdout - 用于调试,输出所有数据到stdout。
GoReplay在猪齿鱼平台的实践
1.1 首先我们先在服务器中安装Gor_1.1.0;
1.2 然后输入命令以下命令:
sudo nohup gor --input-raw :8080 \ # 监听服务的端口(默认网关的端口为8080)
-http-allow-method GET \ # 只录制GET,POST,PUT,DELETE四种方法的请求
-http-allow-method POST \
-http-allow-method PUT \
-http-allow-method DELETE \
-input-raw-track-response \ # 捕获响应报文
-input-raw-timestamp-type PCAP_TSTAMP_HOST \ # 指定时间戳格式
-input-raw-buffer-size 32mb \ # 控制用于持有TCP包的系统缓存大小
-prettify-http \ # 自动解码 Content-Encoding:gzip 和 Transfer-Encoding:chunked的请求和响应
-output-file-append \ # 追加到文件,使得最终只生成一个.gor文件
-output-file requests.gor & # 指定结果文件名称
这些命令的含义是监听服务的端口并开始录制指定的请求类型的请求,例如这里录制的请求类型是:GET,PSOT,PUT和DELETE。捕获响应报文并把这些请求追加到文件,像这里生成的文件名叫“requests.gor”。
1.3 在命令执行后,输出如下:

这里显示的【1】19436是gor程序的进程PID,在我们录制完成后可以利用此PID进行终止gor。
1.4 这时gor已经开始进行流量录制了,此时测试人员可以开始在被测系统进行测试,此段时间的测试发出的请求会被录制。
测试人员在正式录制相关的功能之前,建议刷新页面以请求 self 接口获取当前用户信息,这个接口的响应便于之后导入流量文件时解析用例,如果既没有录制到 self 接口,也没有在导入时提供用户信息获取接口,则在无法解析请求所属用户的情况下,请求生成的用例会被忽略。
1.5 在录制一段时间的流量后,我们执行以下命令终止gor的录制输入一下命令:
sudo kill -15 ${gor进程PID}
像我们这里的输入sudo kill -15 ${19436}命令就可以终止gor进程。
1.6 此时,可以看到执行录制指令的目录下,得到一份文件名为 requests.gor 的流量文件。到此,录制完毕。
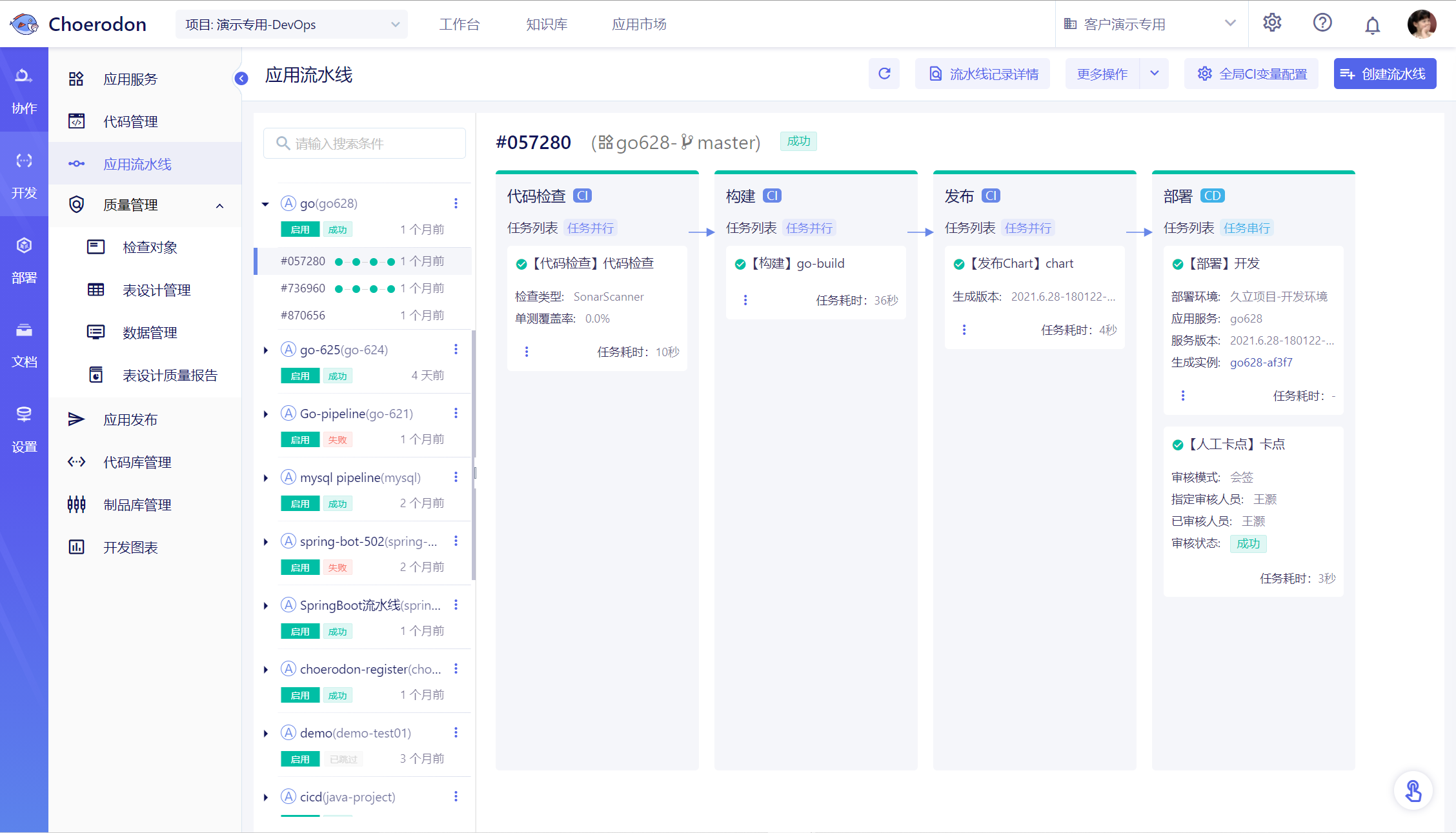
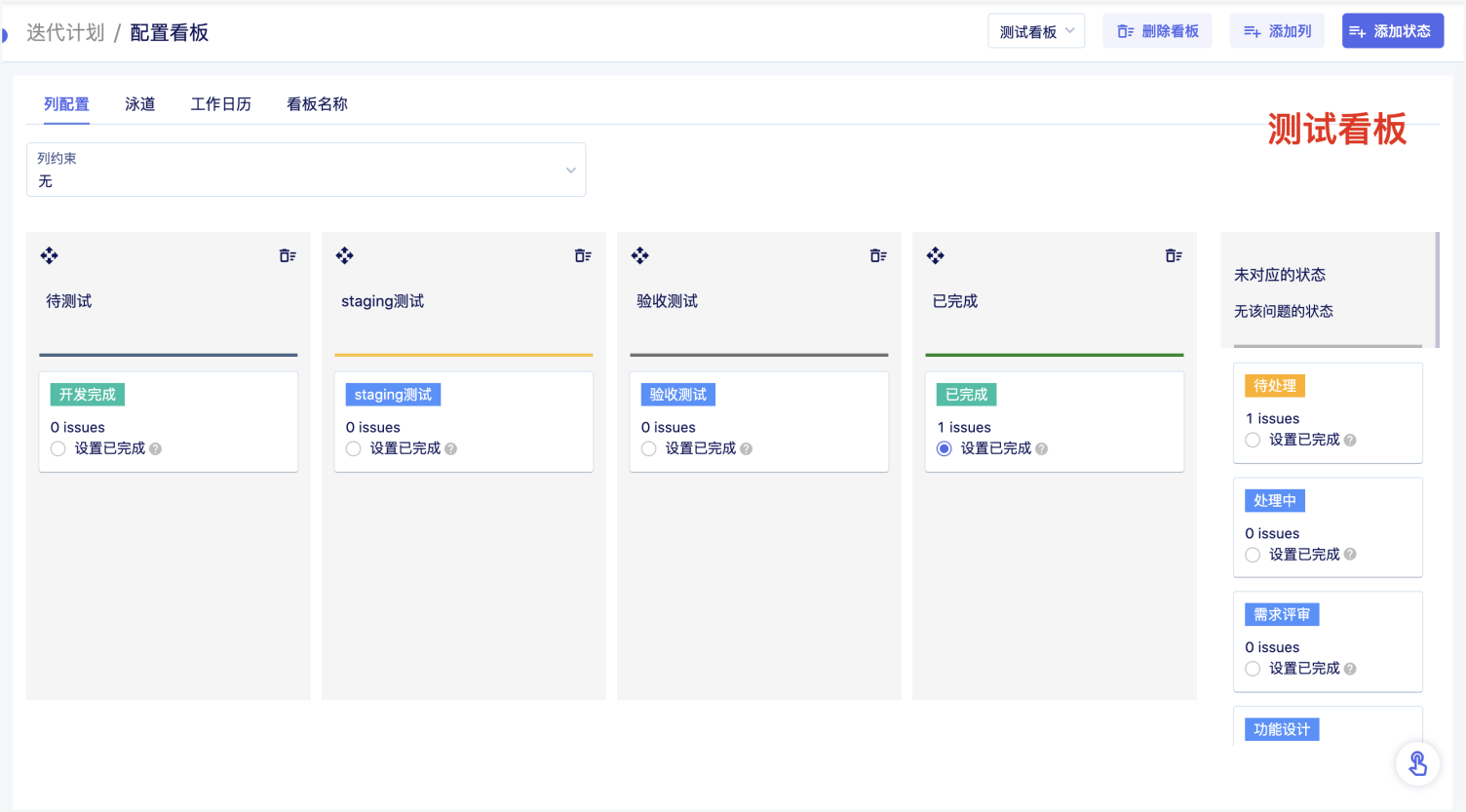
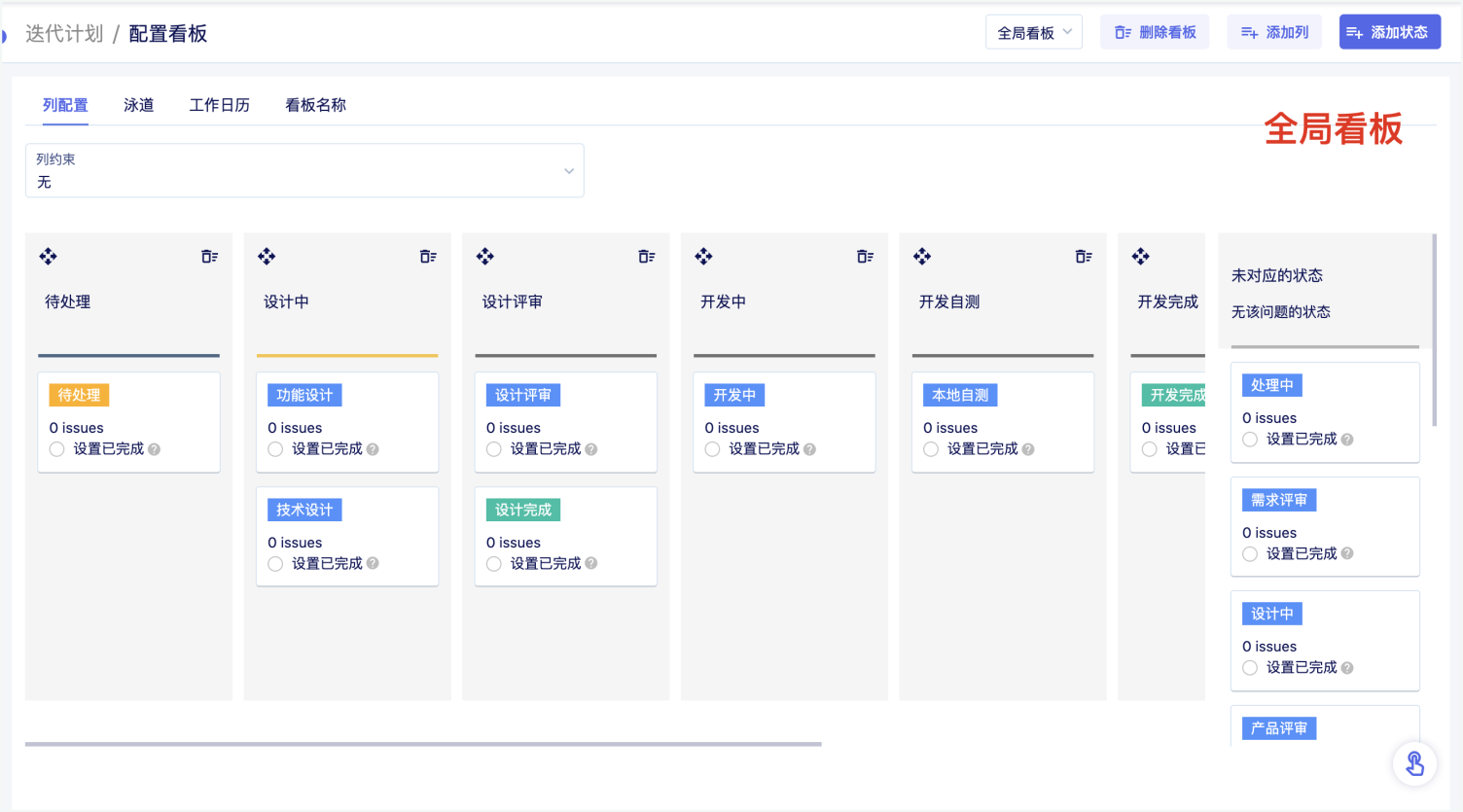
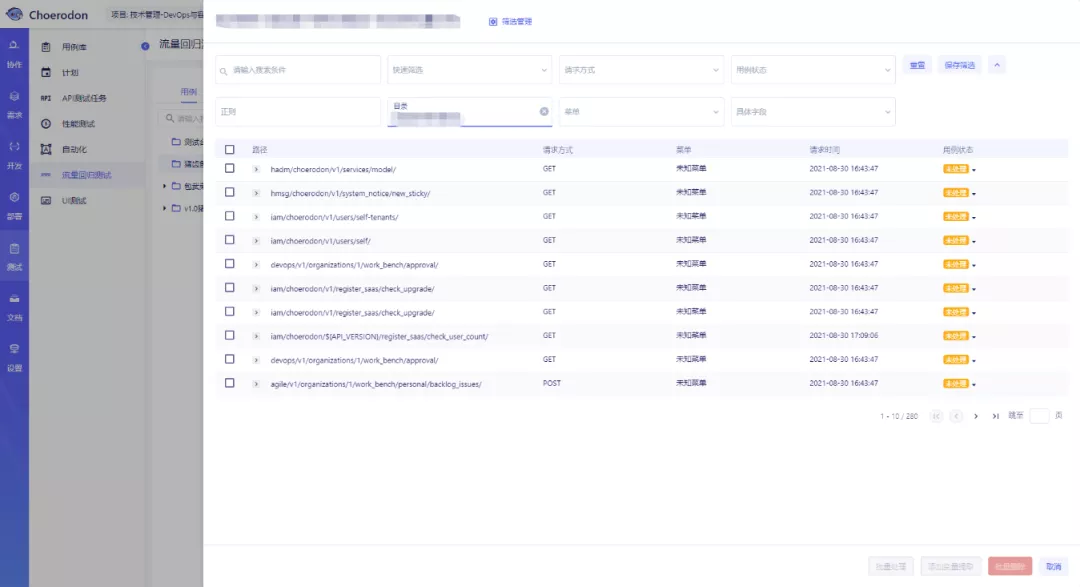
2.1 我们进入猪齿鱼流量回归测试页面:

2.2 点击流量回归测试右上方的导入流量文件,进入流量导入界面:

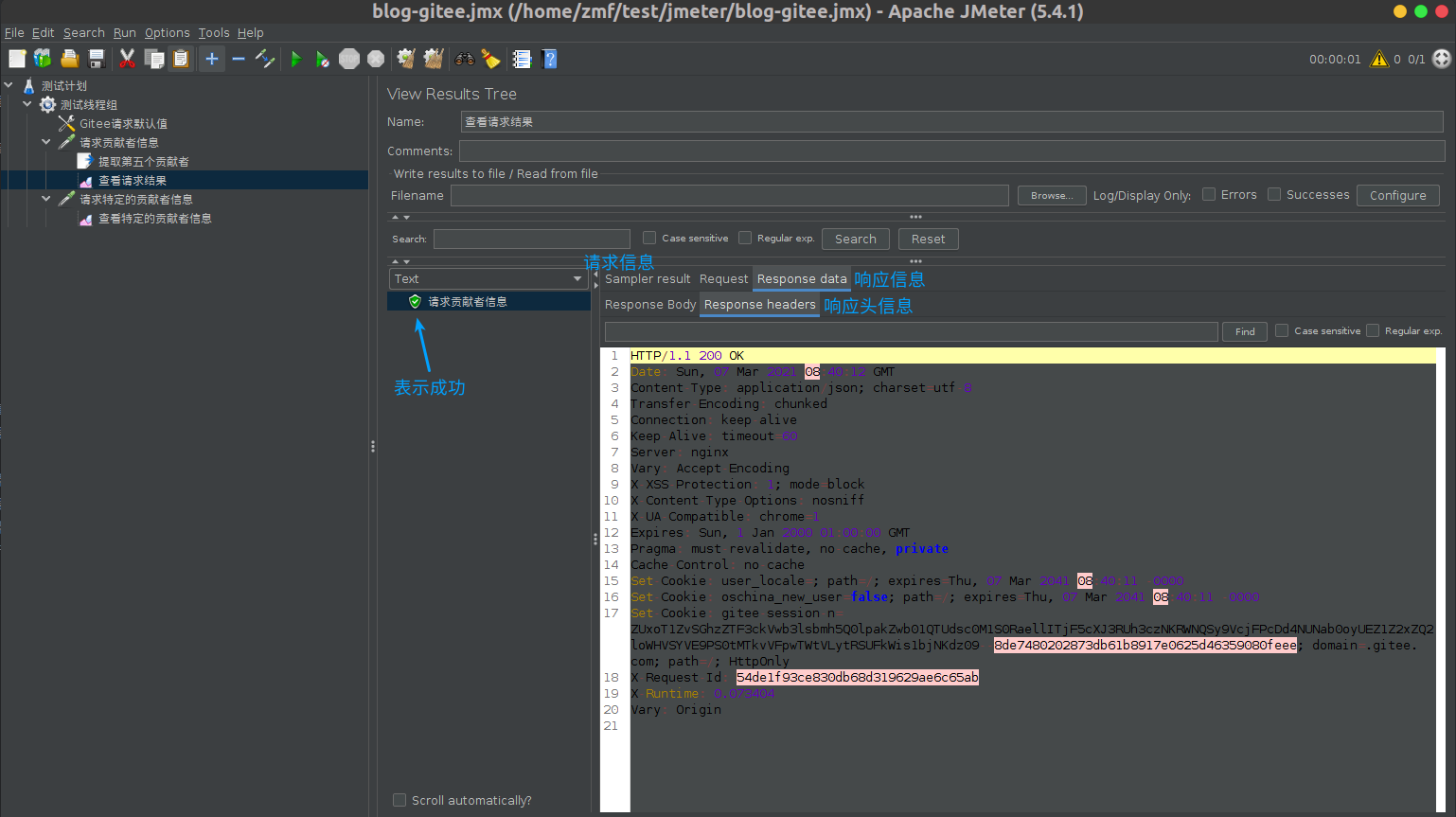
2.3选择选择用于放置生成用例的目录,我们这里选择的是测试合集目录,点击上传按钮,上传我们刚才录制的requests.gor文件,确定上传文件后,下方会立刻生成一条文件的导入记录。

如果导入用例为0条,可能有以下原因:
①录制期间,被测系统未关闭主键加密功能;
②录制期间,未请求 self 接口获取用户信息,且导入时未提供用户信息获取接口;
③提供用户信息获取接口,但是录制的流量文件时间过长,超过了用户的 Token 过期时间,导致流量文件中涉及到的请求的认证信息已经过期了,无法识别用户,所以无法生成用例;
④所有的请求都不是 json 类型的请求
⑤所有的请求的方法都不是 GET、POST、PUT或DELETE
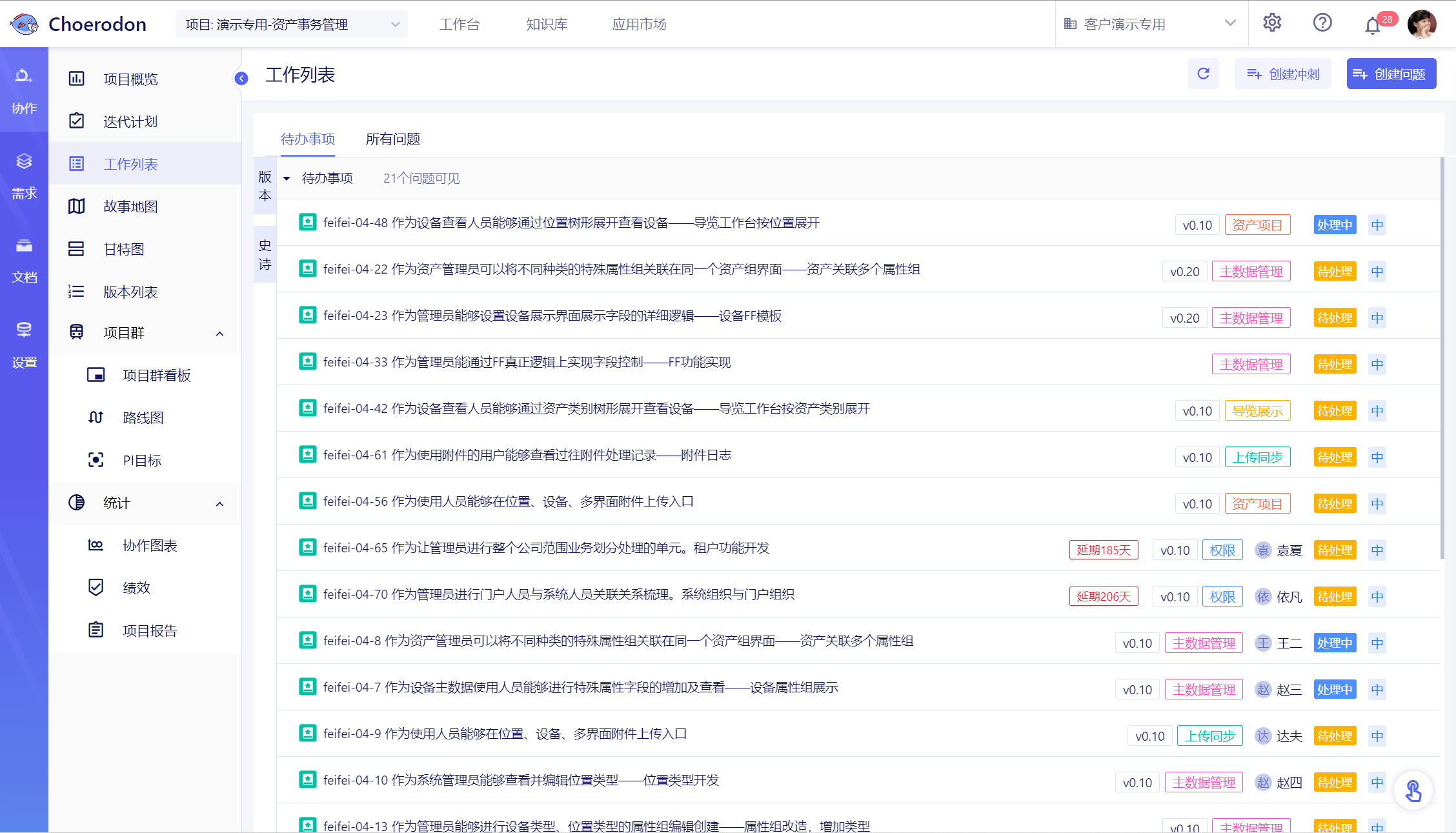
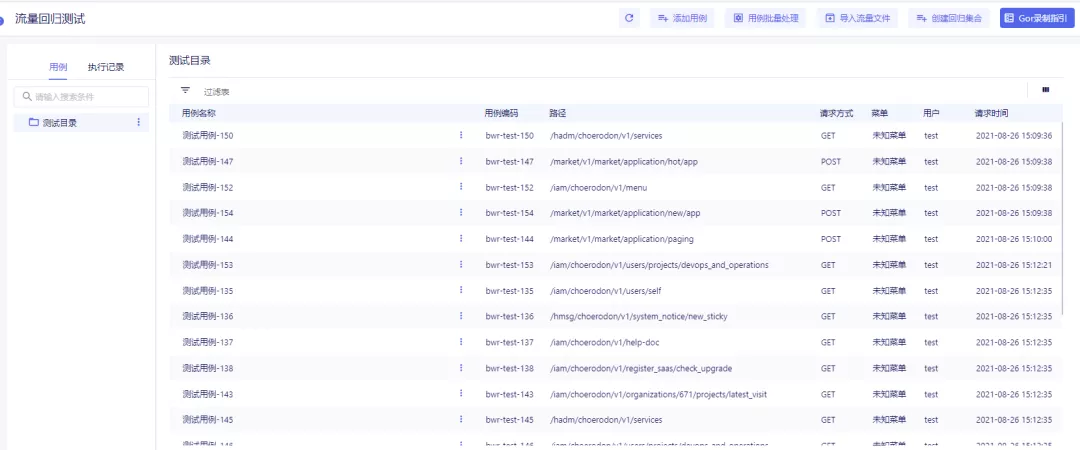
2.4 待文件导入成功后,所选的目录下将会生成对应的用例。列表中会展示各个用例对应的路径、请求方式、菜单、用户以及请求时间。
- 路径:即用例中请求的路径。
- 请求方式:即用例中请求的请求方式。
- 菜单:即用例中对应请求所属的菜单。
- 用户:即在录制过程中,执行此次请求的用户名。
- 请求时间:即录制过程中,该请求对应的执行时间。
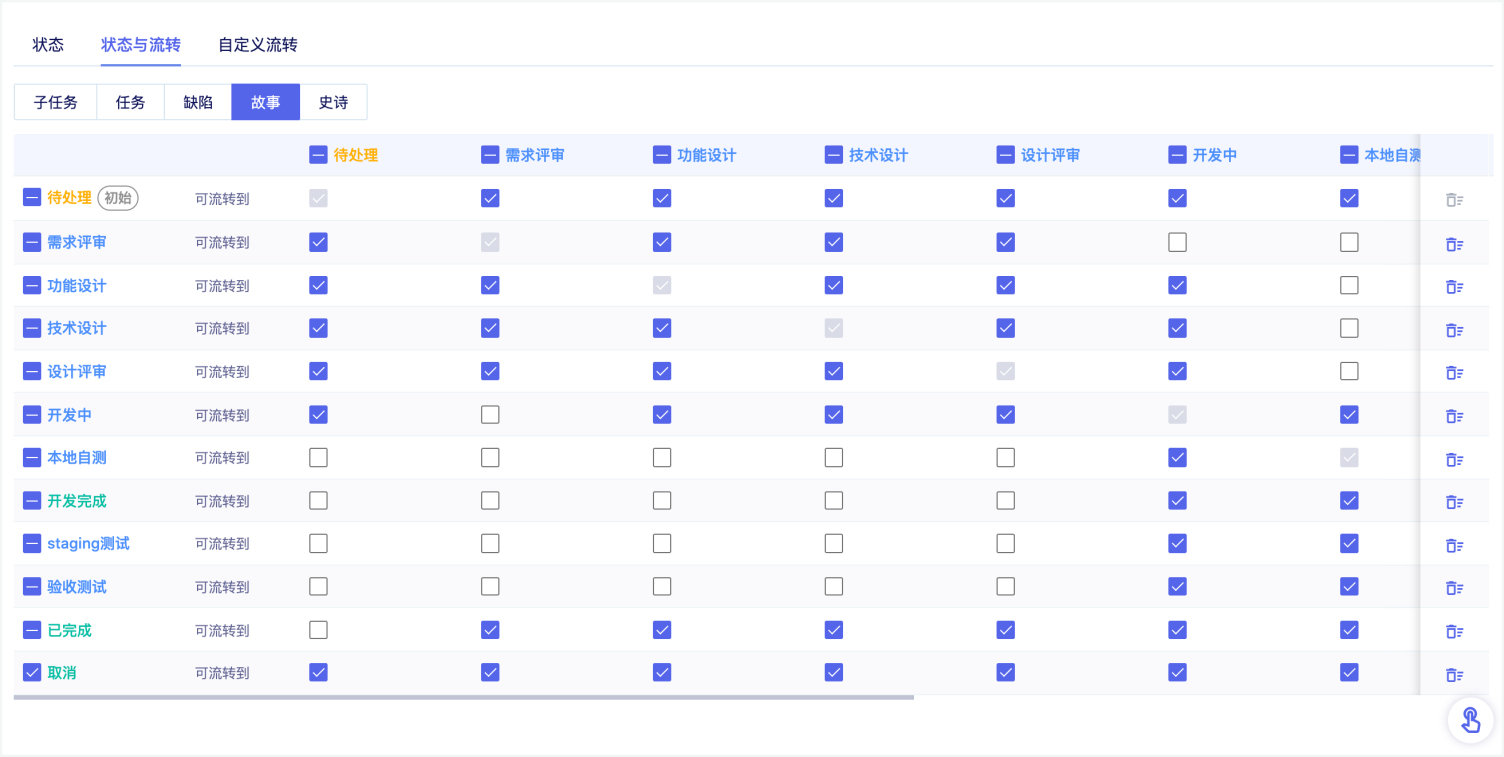
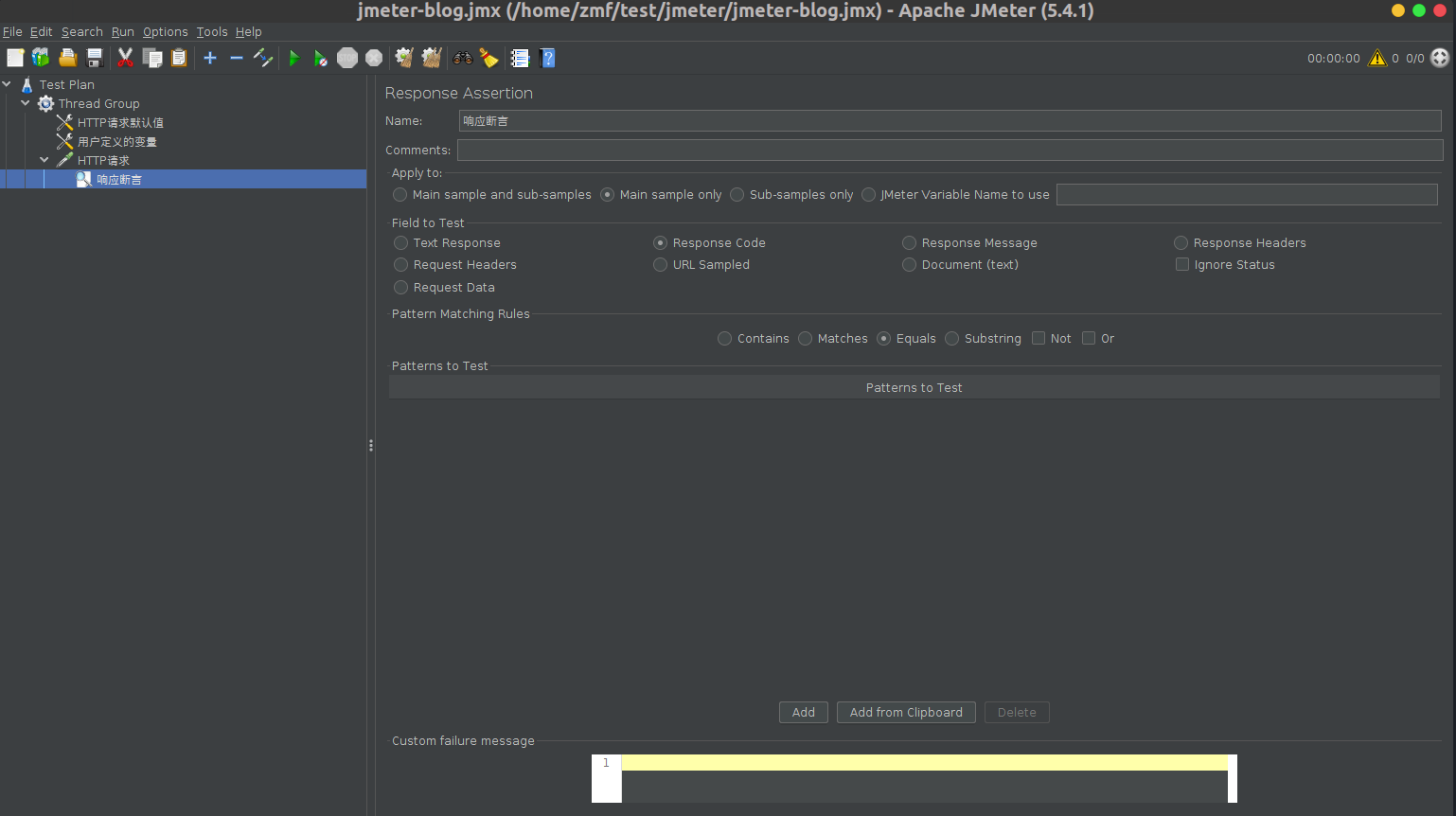
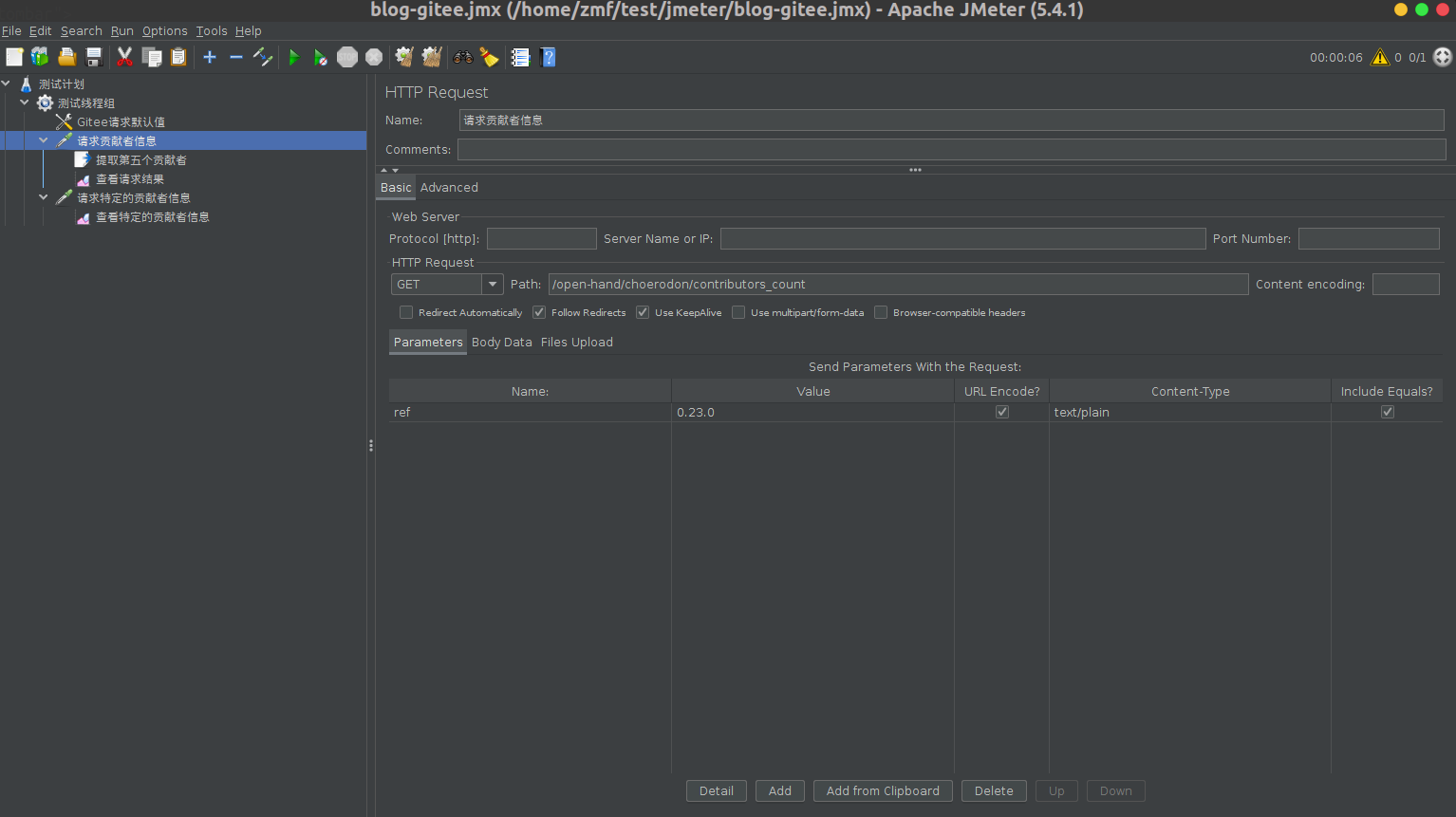
3.1 由于我们通过导入流量文件得到的用例内,各个请求�使用的ID参数在之后的执行过程中会产生变化。因此我们需要通过用例批量处理的功能将用例内各个请求路径、请求参数、请求体中的ID参数替换为变量。
在此之前,我们还需要选择一个POST类型的请求,将其响应体中生成的ID作为变量提取出来,以供后续的用例进行引用。
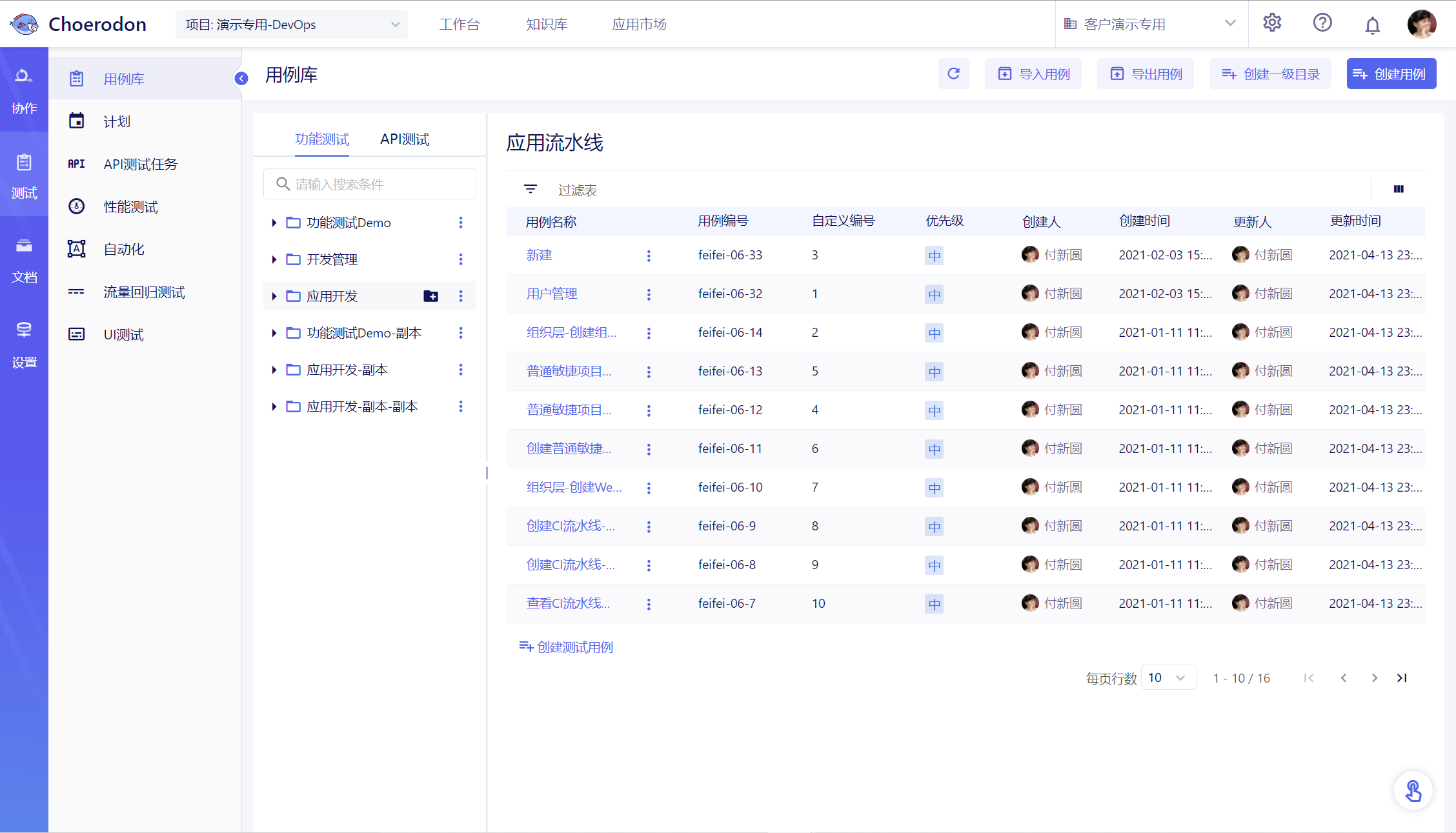
首先在页面左侧的树结构内选中一个流量回归集合,而后点击顶部的用例批量处理按钮,右侧会出现批量处理的页面。
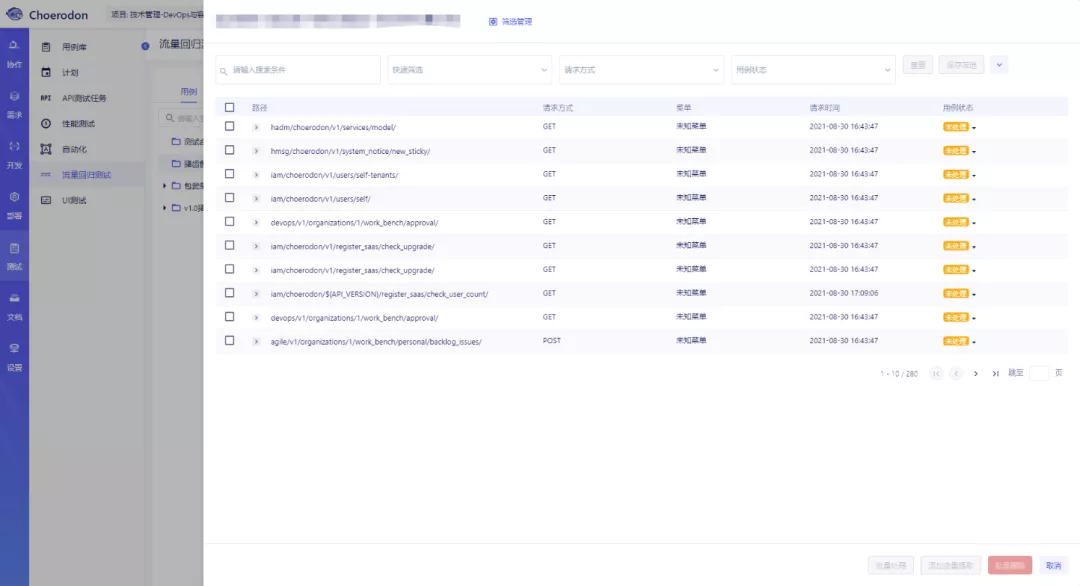
3.2使用搜索栏进行用例筛选,支持的搜索方式有:
- 输入搜索条件查询:可搜索任意内容,下方的列表中将会显示出路径、请求与响应中含有搜索值的对应用例。
- 快速筛选:预置的快速筛选为
含数值用例,可直接搜索出路径、请求与响应中含有数值的所有用例,用于帮助进一步缩小ID查询范围。同时,保存的自定义筛选条件也将存放到快速筛选的下拉框中。 - 请求方式筛选:允许筛出GET、POST、PUT与DELETE类型的用例请求。
- 用例状态筛选:支持筛选出
处理完成或未处理状态的用例请求。 - 正则筛选:支持使用正则表达式来筛选出满足条件的用例请求。
- 目录筛选:支持筛选出各个目录下的用例请求。
- 菜单筛选:支持筛选出对应菜单下的用例请求。
- 具体字段:用于指定搜索值的定位生效区域。支持定位到:路径、请求头、请求参数、请求体、响应头与响应体。
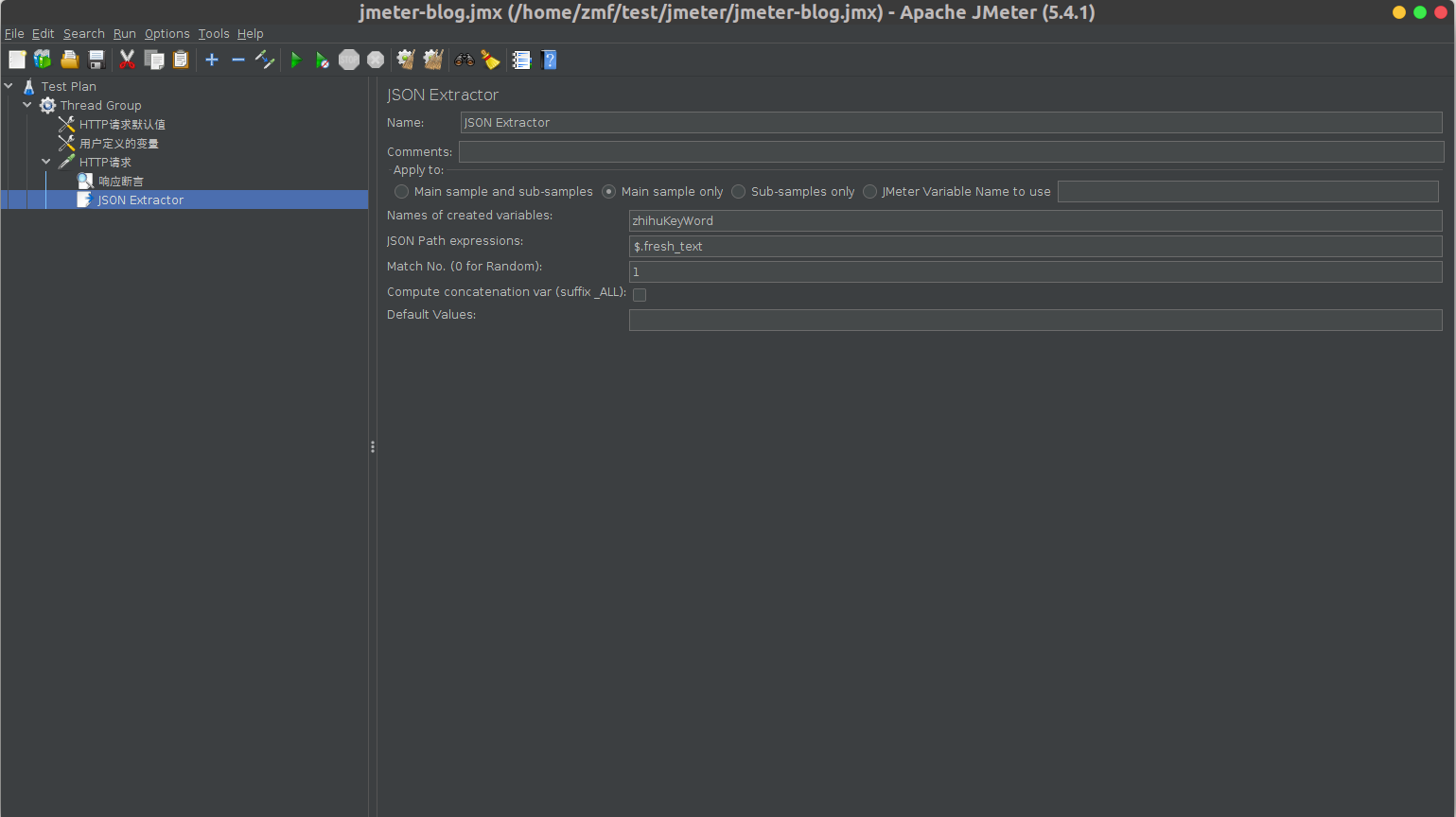
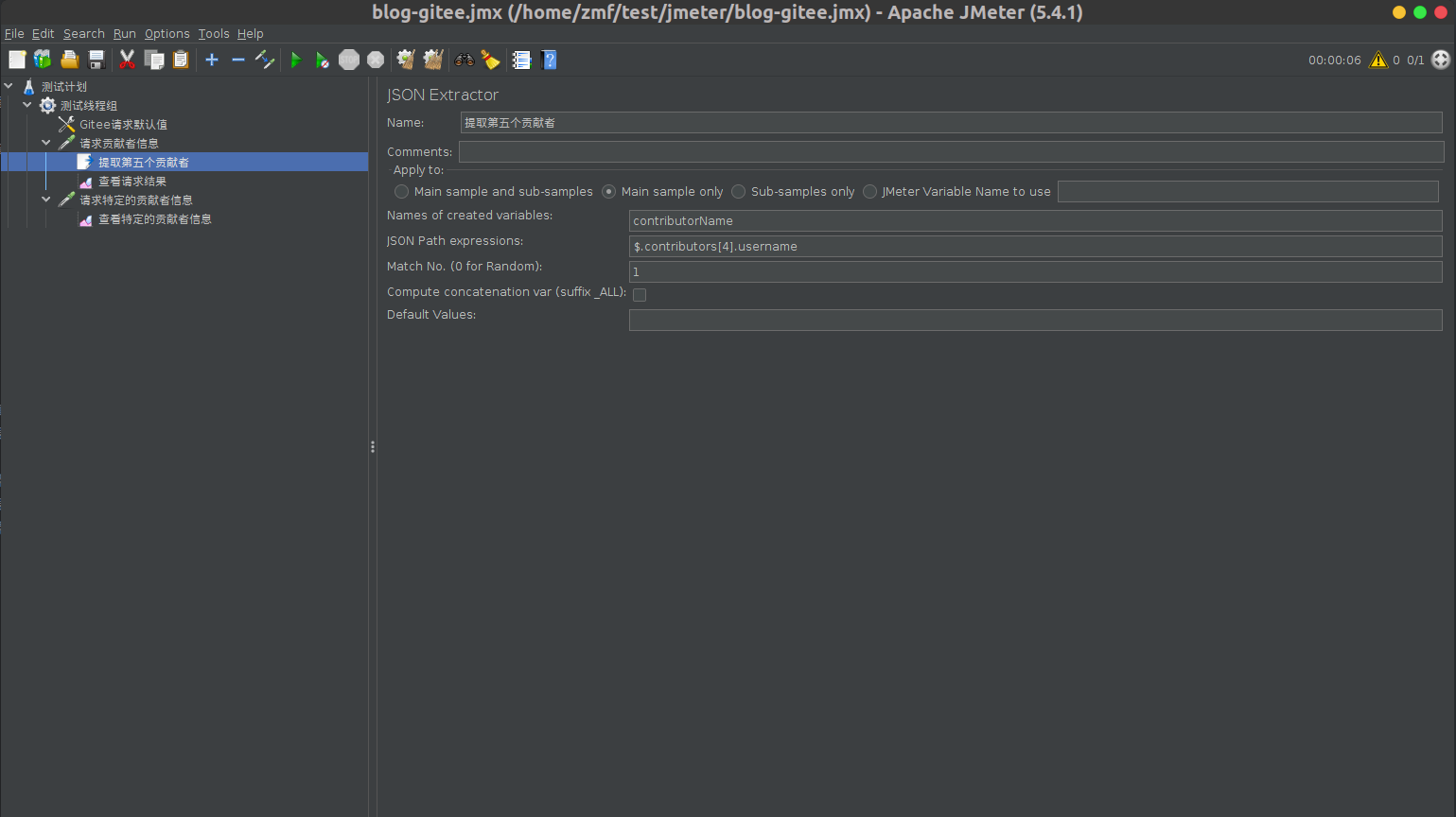
3.3提取页面中的变量,在此界面中,需要将生成ID的用例请求找到,并将其响应体中的ID参数作为变量提取出来。具体步骤如下:
1.通过搜索栏中的各个选项定位到目标用例。
此处的一般步骤为: - 在快速筛选的搜索栏中选择含数值用例,先筛出所有含有数值的用例。 - 在具体字段中,选择为:POST,以筛出目标用例。 - 选择想要处理的功能块所在的菜单,或在搜索条件中输入相关内容,来进一步缩小搜索的范围。 - 最后,在筛出的用例请求中逐一找出目标用例。
2.勾选出一个目标用例,点击下方的添加变量提取的按钮,右侧会弹出变量提取的界面。
选择提取的来源:一般为响应体JSON,此处需根据提取的目标变量的位置与格式而定;支持选择响应体JSON、响应体XML、响应体文本与响应头。
输入变量名称:此处输入的变量名称,会作为后续用例引用的变量。
选择器:需通过选择器定位到提取的变量所在的位置。
变量提取成功后,还需要对请求中使用了ID参数的用例进行批量的ID替换,将其替换为提取出的变量。
使用此功能,可以批量地将可以配置的参数提取为变量,例如提取请求中常见的项目ID、租户ID或者其它的资源ID。
总结
猪齿鱼全场景效能平台流量回归测试通过GoReplay批量录制产品界面操作,并将得到的用例进行集中管理,便于后续进行批量的回归测试,从很大程度上减轻了测试人员编写脚本、收集测试数据等重复且耗时的工作,提升团队的测试效能。
参考资料
欢迎免费试用SaaS企业版
试用链接:https://choerodon.com.cn/register-organization/#/
关于Choerodon猪齿鱼
Choerodon猪齿鱼是基于Kubernetes,Istio,knative,Gitlab,Spring Cloud来实现本地和云端环境的集成,实现企业多云/混合云应用环境的一致性。平台通过提供精益敏捷、持续交付、容器环境、微服务、DevOps等能力来帮助组织团队来完成软件的生命周期管理,从而更快、更频繁地交付更稳定的软件。
大家也可以通过以下社区途径了解猪齿鱼的最新动态、产品特性,以及参与社区贡献:
Choerodon猪齿鱼官方社区用户交流群,此群可交流猪齿鱼使用心得、Docker、微服务、K8S、敏捷管理等相关理论实践心得,群同步更新版本更新等信息,大家可以加群讨论交流。
请添加Choerodon猪齿鱼小助手微信:hand-c7n

欢迎加入Choerodon猪齿鱼社区,共同为企业数字化服务打造一个开放的生态平台。


 图:猪齿鱼-工作日历
图:猪齿鱼-工作日历 图:猪齿鱼-查看工作日历任务
图:猪齿鱼-查看工作日历任务 图:猪齿鱼-可将工作日历订阅到本地Outlook
图:猪齿鱼-可将工作日历订阅到本地Outlook 图:猪齿鱼-工时日历
图:猪齿鱼-工时日历 图:猪齿鱼-甘特图
图:猪齿鱼-甘特图